Today we welcome Yasir Anwar, former CTO and Chief Data Officer for Williams Sonoma, to The CXO Journey to the AI Future podcast.
Yasir Anwar is an innovation enthusiast who is an Entrepreneur at heart and a Technologist at execution. He considers himself on a D.I.E.T (Disruption; Innovation; Execution; Technology Excellence). To keep the balance between solving technical issues and shaping an overarching strategy, he strives to switch roles between being an engineer, architect, and C-Level Executive as needed. He believes this keeps himself humble, realistic and truly connected with his teams.
Most recently he was the Chief Digital and Technology Officer for Williams Sonoma Inc. leading all digital, technology, and IT functions. Before this, he was the first CTO for Macy’s, where he drove the growth of e-commerce channels, and omni-channel capabilities and led the merger of the previous digital and CIO organizations under one mission and culture.
Yasir is also a Lean practitioner at scale and established the LeanLabs culture at Macy’s which grew from one LeanLabs team to 40+ teams contributing significantly to an increase in revenue, cultural agility, and innovation.
Question 1: Current Job: Could you tell us a little bit about your background and how you ended up where you are today?
This career is what I’ve always wanted. I’ve tried to work towards being both an entrepreneur and an execution person, and it has taken a lot of work to get to where I am today.
I started as a core engineer in C++, Java,…all those languages and databases. And I’ve always believed that everything I’m doing must make a business impact (whether it’s internal or customer-facing revenue development). It can’t just be a shiny object or an academic exercise.
So, I’ve tried to make an impact via tech innovation, and more importantly, always measure it. I’ve always focused on how to better devise mechanisms, culture, and frameworks in order to facilitate continuous measurement.
That has been the core thread of the career I’ve developed. In all the leadership roles I’ve had, whether at Walmart, Macy’s, or William Sonoma, making an impact was ultimately accomplished by building great teams and a great culture, while still being capable of partnering with the broader ecosystem.
Question 2: Generative AI: Of course, here in the valley AI is all the rage. San Francisco has several new startups that are AI-focused. But you’ve been through quite a few technology journeys of your own. How much priority do you think we should be putting on this?
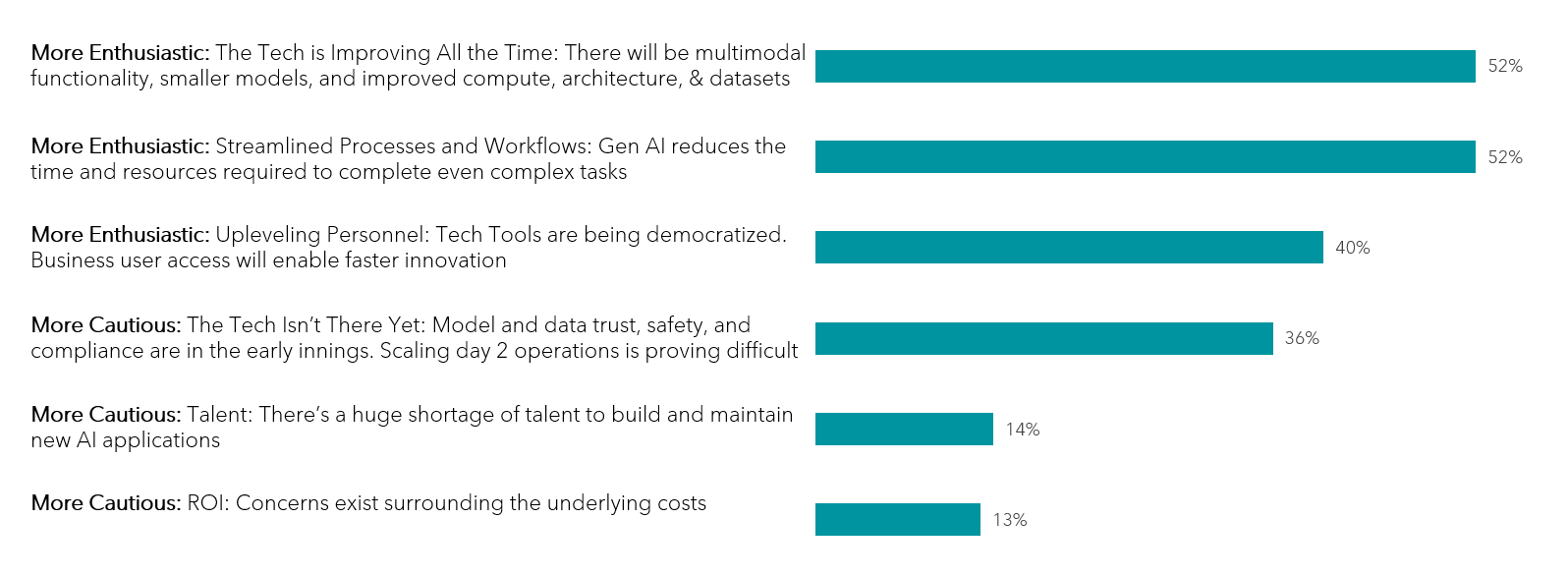
I think generative AI is critical to the growth, evolution, and innovation of any business. If you look at it from a time series function, last year was a year where companies and businesses should have invested in exploring and understanding the art of the possible in both the near-term and the long-term.
2023 was a year of exploration for most of the people who are not producing core AI solutions. I envision that over the long-term, generative AI will drive a paradigm shift of resources, mind share, and time investment throughout companies of all sizes. Today, the majority of businesses are focused on core operations, and only a small periphery is spent on growth and innovative initiatives. I strongly believe that generative AI has the potential to alter resource investment in growth and innovation at a scale that we haven’t experienced in the past.
This could be very different from many other technologies that came before. It has a much larger impact on every aspect of a company’s operations and consumer functions. I also think that it will free up time and resources through automation and collaboration tools.
We also know that consumers are being rapidly trained with AI-powered experiences and the expectations are going to climb very soon. In a 3 to 5-year period, I do see a paradigm shift in time, resources, and mindshare deployed to emphasize growth, innovation, and newness powered by AGI.
Extra question: You shared an image with us. Could you explain the key points? I know you’re talking about this growth mindset of AGI really transforming how we think about innovation.
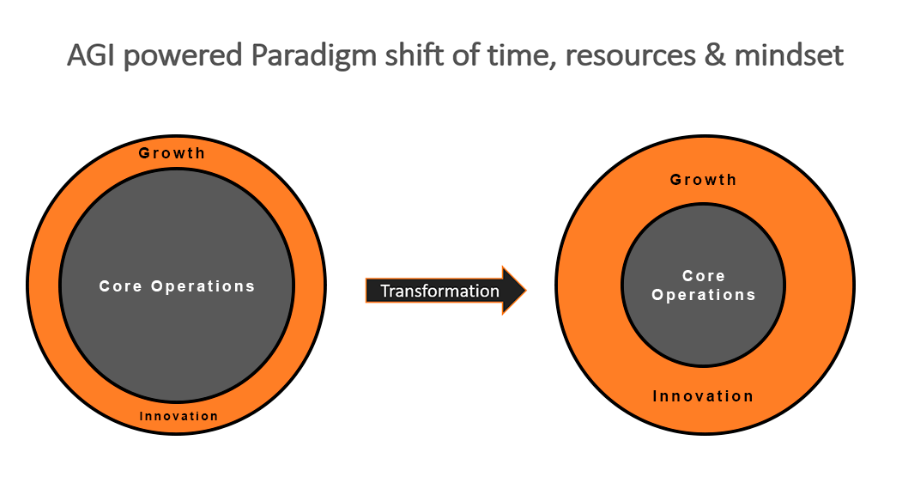
I see a business as two concentric circles. One is core operations and on the periphery is growth, innovation, and newness. This is backed by the data with companies traditionally growing around 6% – 10%. Only some startups have meteoric growth.
However, with the deployment of AGI, the core operations inner circle is going to shrink. Mundane tasks will be reduced and growth and innovation will increase at a very significant scale, because now the right tools will be available for it.
Question 3: Early Learnings: You make digital transformation the first stepping stone to true business transformation. And AGI is the catalyst, the enabler of that. While at William Sonoma you deployed some AGI initiatives. Do you have any early learnings?
First, I think that for every layer of technology that comes in you need a team, and you need yourself to be aware and have learned and gone through the process of building some expertise for all the previous technologies. So it’s microservices, platform data, big data, AI in general, machine learning…
Then, AGI comes as an additional layer on top of all that. You have to start by establishing a test-and-learn model with a small team approach – hopefully, if you’re reading this, your company has already started.
I also think it’s key to establish and prioritize relevant and valuable use cases, and to understand where generative AI could help. These use cases need to be quickly paired with LLM solutions vs. people just talking about what could happen. Not everything will work out, and that’s okay. You need to look at what is promising and then set a test-and-learn iterative approach to shape the product or feature your teams are working on.
Extra Question: What is ready from an AI perspective (the models and LLMs available)? And what are your relevant use cases?
For retail in general, it has been content generation and product descriptions. They have proven to be very, very productive. A chatbot helps not only by just checking your order but also some product expertise can be outsourced to that. Designing the look, shoppable images and videos, buying the look, buying the experience, searching, and recommendations improvements by applying AGI and LLM models, have all been very important aspects of the work. Also, 3D and photo-realistic imagery is becoming very common now.
On the other side, supply chain and operational efficiencies are being improved upon by predicting and optimizing shipping delivery routes (which used to be a very transactional table in the past). Now you can dynamically learn what is the best route for delivery. You can also do some returns, prediction, and accuracy, which will help you throughout your entire supply chain.
You could boost associate productivity through code co-pilots, which we tried, and collaboration tools to optimize communication. There are companies now that are talking about inside retrieval from all the documentation that’s available, and providing you with suggested actions that you can pick and choose from.
Talent acquisition and talent management have also come up as a new topic where AGI is being deployed.
Question 4: Metrics: I presume there are a bunch of use cases that you had to challenge inside of the organization. How do you rationalize the list of use cases? Did you apply some business metrics to them? How did you prioritize?
I think the easiest thing to pick is where you already have a pain point in the business. Then you try to look at it from both angles, as I said.
One is defining the problem. I think we should always stop and start with the pain removal, before diving into growth.
As a technologist, your job is to figure out what technology is ready. For example, what kind of element models are ready for this deployment versus others? You can spend cycles and months and months, and you find that the lift was only 2% which you could have done by changing the color of the button on a screen, for example, or a location.
So the metrics are important to your point, and I believe that generative website experiences are going to be an area that’s heavily impacted. So I envision that the typical search bar on the website is likely going to go away. It will be more of a generative website experience where you’ll find more relevant and personalized results. So search, recommendations, and chatbot are all going to be meshed into a more generative website experience based on the time of the day, your original location, if you are traveling, or if you’re on an iPad versus a phone.
It’s about giving the customers something very relevant in order to lift the conversion through the roof. That’s the current opportunity for AGI.
Then, the entire commerce funnel has clear KPIs at every step already established. For example, conversion at every step of the funnel: AOV, AUR, category penetration, shipping costs, etc.
Still, while deploying generative AI at each of these commerce steps, we can’t only measure the KPIs as we used to. In the past, you would usually deploy something and achieve a 3-4% conversion lift, or, revenue-per-visitor for that particular small step.
I believe the power of AGI to validate is that its impacts have to be at a much larger scale and pace. For something you were trying to do over 6 months, the way I would vet an AGI solution, in the beginning, would be: Are you shrinking my cycle from 6 months to 2 months? Or one month? Or are you talking about a 5% lift and you’re bringing an additional newness to my solution and experience that could give me anywhere from like 20 to 50% growth across that segment?
I think that’s the way you look at metrics here. And if you can even reach the halfway mark, I still think that’s a fantastic success vs. still trying to just get a 5% lift in conversion. Avoiding bias and cannibalism of other KPIs over a period of time is an important thing to watch as well.
Another important category in my mind is the analytics to track the AGI progress. I think there needs to be a shift from existing transactional reporting to more predictive trend analysis, facilitating better planning and decision-making.
Question 5: The ‘Buy versus Build’ concept: There’s a technology decision as well. You are the technology leader and in all of this effort at some level, you have to decide: Do you go with existing vendors? Do you take on some of these new vendors? Do you build your own model? What’s the ‘buy versus build’ thesis that you believe we should be thinking about? How do you go about making all of those decisions when it’s an early adopter market?
I practice a balance of this because you can’t be just a buyer person–you don’t need to be a technologist to be a buyer. However, if you’re just building, then you get too much into the weeds of proving yourself and your teams.
Everyone is new in this space because it’s all new. However, I believe that over 50% of the enterprises that have built LLMs from scratch are likely going to abandon their efforts due to cost, complexity, and technical debt. It’s not going to be manageable.
So these foundational ecosystems, like OpenAI or Azure providing a view into OpenAI, or some niche companies who have built on top of OpenAI, are credible. These provide you with a safe playground. They also provide you with learnings from their own data, and models at an unprecedented scale. You can’t compete with the data Google has, or Azure brings, etc.
That being said, you could deploy all your inference models and orchestration LLM models on top of their models to add even more value and specialized results for your business and problem space.
That’s the build versus buy combination.
You’ve got to watch it. But at the same time, I believe that if you don’t build muscle internally, then at some point you’ll just be running blind. You won’t know what you’re doing and you’ll be trapped working with all the major brands. So it’s also important that there are groups of people within the company who continue to evaluate and approach the latest and greatest open models for relevant business cases in order to validate the offerings from the large ecosystems and vendors. This ensures that you’re not missing out on something difficult on account of suffering from vendor lock-in.
Question 6: Gaps and Issues: What do you think some of the gaps, issues, or impediments are for large organizations? I know this isn’t a technology-only issue. What are some of the issues, or maybe even gaps in technology, that you believe need to be addressed?
I think the overall core talent pool is very small, and by this I mean people who know the guts of data and the guts of AGI. Tools like ChatGPT make it seem easy. The talent that says “I can get started by generating great prompts” is plenty. You don’t need to be a technologist to do that. But the core talent, to my previous point, is still very small.
However, for any large-scale enterprise, it’s critical to have some core talent that understands the guts of AI, the anatomy of these LLM models, and, more importantly, the criticality of data preparation.
So I think companies should also invest in their existing deep experts in data and platforms and get them motivated and trained on AGI. That will help integrate them with a new generation of LLM engineers. So the total product as a team will be more holistic, versus just rushing towards building LLM models.
To me, this remains the biggest challenge for most companies. And this despite all of the investments in the past decades that I’ve seen in data lakes, and data oceans or pools, whatever they’ve created. Still, your results and LLM insights are going to depend on your data. So preparing that data and the quality of that data is going to be very important.
Question 7: Responsible AI: We talked about bias and hallucination, trust, and risk governance issues. What do you think about responsible AI? And what message would you give to your senior leadership on how they should think about it?
From a business perspective, the scale of impact of AGI has to be much larger than the normal projects you would do in tech investments. And that’s the promise it should bring. Therefore, it must be vetted.
For that reason, I don’t even like to call it artificial intelligence. I’d rather call it Accelerated Intelligence, because that’s what it should deliver. If it’s not giving you accelerated intelligence to make an impact, then why even bother building all of these models?
AI should have constructive business goals and measurable KPIs and transparency. If you can, up front, define that this is the part that an LLM model is going to produce, and you can measure and provide that transparency to your business partners and leaders, I think they will come along for the journey. They will want to get trained and educated. They can even bring their own insights, and challenge you with the right insightful questions about the KPIs and measurements.
Don’t treat it like a black box: “We’re doing some research, and we’ll tell you where we find a nugget.” Rather, be upfront and defined. If there are seven failures, it’s good for the company to know that it’s not mature yet, even though our teams have tried seven times. Or you want to be able to say: “In this particular domain, it is mature, and it is giving us results, and the results are realistic.”
When it comes to the responsibility of AI, there are other aspects to consider as well. It needs to be protected from biases and corrupted training data or user feedback, which is called data poisoning or prompt injection attacks.
So it’s important to transparently define both of these issues in order to ensure correct outcomes across the various stages of development and deployment. Large vendors and ecosystems will need to focus here as well.
Another important aspect is that generative AI and its proliferation poses a big risk to organizations as it provides a significantly larger attack surface for cybersecurity issues.
It also provides a new attack vector, where it’s much harder to identify anomalies. So to me, data should be protected all the time and for any new deployment. One of the types or ways to approach this is that we should implement a safe test-to-learn approach with only necessary data provisioned in a sandbox environment. The solution runs to understand the scale of the idea and the impact and validate its safety before we roll it down to the full dataset of the organization, domain, or department.
Another idea I have is that there should be guided AI-type platforms like OpenAI. I believe there is an overarching need for these platforms given it has such a global impact. In parallel to OpenAI, this guided AI platform can govern all AGI implementations in an enterprise, map them each to their planned outcome, and then also catch signals proactively.
Even 100 implementations may cause long-term deviation from company goals.
If you implement AGI across many different departments, individual teams may be doing fine, but not aligning with top-level initiatives. You might have the goal of driving operating margins in a particular direction, and two individual teams could be polluting everything, even if the rest of the solutions are working fine.
There needs to be a parallel platform that can provide this guidance watchtower aspect, and that is not specific to any specific company. It’s a larger platform that could be deployed in enterprises and would watch out for every level of possible anomalies and deviation from a specific implementation of an LLM, but also tie it back to overall company goals, and see if any of the LLM implementations by themselves, or combined, may muddy the waters.

Yasir Anwar is an innovation enthusiast who is an Entrepreneur at heart and a Technologist at execution. #Techpreneur
Yasir is on a D.I.E.T – Disruption. Innovation.Execution.Technology excellence.
Yasir is shaping the strategic technical direction of the companies and transforming technology for the next generation of retail – the world of connected commerce. Yasir has led end-to-end business and digital transformation for companies through technology excellence, innovation, and digital prowess focused on customer experience.
Most recently he was the Chief Digital and Technology Officer for Williams Sonoma Inc. leading all digital, technology, and IT functions. Prior to this, he was the first CTO for Macy’s, where he drove the growth of e-commerce channels, and Omni capabilities and led the merger of the previous digital and CIO organizations under one mission and culture.
Yasir is also a Lean practitioner at scale and established the LeanLabs culture at Macy’s which grew from one LeanLabs team to 40+ teams contributing significantly to revenue increase, cultural agility, and innovation. Before that Yasir had many leadership roles with WalmartLabs, SamsClub.com, Walmart.com, and Wells Fargo, and executed large-scale projects across various domains like manufacturing, ERP, Auto Industry, Learning Management Systems, etc.
“If people are not laughing at your goals, your goals are not big enough.”