

Over the past 6 months we’ve hosted several CXO Insight Calls around the topic of AI. However, there’s a real need to solve a number of core issues before enterprise IT leaders can adopt and move to production. According to Forbes, 55% of business leaders say their teams are resistant towards adopting AI today. It’s not hard to see why.
Our goal with this discussion was to move beyond the high-level conversations we’ve been discussing over the last 12 months and hear from a few leading startups on how to leverage external technology to drive practical advances in AI today. What’s the reality a year and a half in?
We were joined by Rehan Jalil of Securiti.ai, who covered his perspective on leveraging xStructured data, Rob Bearden and Ram Venkatesh of Sema4.ai on agents and automation, and Vin Sharma of Vijil.ai on trust and safety…so let’s dive in.
Our thesis in AI is that AI + Human = Human², and that instead of displacing today’s workforce, AI should be used to elevate human productivity. The first wave of AI, which arrived over a decade in the past, was all about the robotic automation of tasks. Today, we’ve made it to the point where we have co-pilots (or AI assistants). In the future, we believe that there will be digital coworkers with humans as assistants – unlocking employee potential to work on more meaningful tasks. We’re calling this new AI era “Cognition-as-a-Service.”
While this is very new, in the past, we’ve followed similar waves of technology. There was infrastructure-as-a-Service, followed by platform-as-a-service (focused on developers), then software-as-a-service (focused on line of business users). And in this new era we’ll have cognition-as-a-service, and the first block is going to be cognitive cloud infrastructure.

Looking at our AI stack, let’s zoom in bottoms-up:
We had three companies join us on our call and speak to different aspects of this stack: the models, the data layer, and the middleware. In the future you’ll be hearing a lot more from us around intelligent applications and the future of agents (or digital assistants). The end game may very well be a hybrid workforce, where we humans will have these digital workers as our teammates.
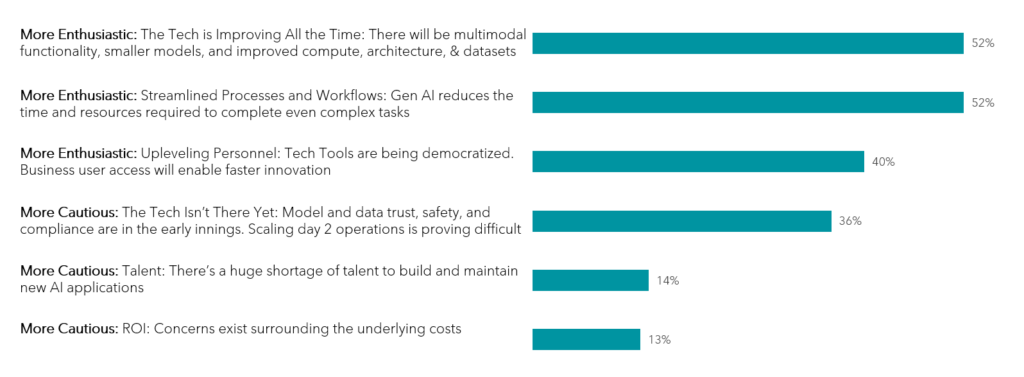
We think that there will be endless possibilities over the next 15-20 years in this area and are looking forward to seeing what everyone comes up with. To kick off our call, we ran an audience poll (150+ responses) to get a sense of how optimistic vs. cautious the audience was with regards to their upcoming AI initiatives. Generally speaking, it seems everyone is looking forward to the future.
Today, organizations across the globe are eager to utilize their proprietary data with LLMs in order to generate value. Unfortunately, this requires the need to have proper visibility and manageability of both structured and unstructured data – particularly unstructured – which is now center stage. How do you deal with figuring out where your unstructured data lives? Or what data you have available? Or how to bring that data into new gen AI pipelines?
One approach could be a knowledge graph. Imagine: all your data in different environments, organized to include an understanding of what files live where, what kinds of sensitive information they might contain, what types of files they are, what purpose they have sitting within the organization, what the applicable regulations are around that data, and even the enterprise data processes that are operating on top of it all. This is Securiti.ai’s approach: the data command center.
Via this command center approach, it’s possible to ensure stronger data security, data governance, data privacy, and the monitoring of unstructured data. So, where does gen AI come in?
The advanced modern gen AI application is going to need to take data from anywhere, data that’s sitting across all these different systems, and combine that data with your custom models to create all the exciting new innovations on top of them – even creating new agents or assistants.
Today, organizations are trying to build their own knowledge systems or applications where people can go to ask simplifying questions. Or, they’re using these data pipelines to tune existing language models. Very occasionally, you’re even seeing a few companies training their own custom LLMs using this infrastructure – but that requires the data to be actually brought into the mix.
In the past, structured data was used for business intelligence, and the whole ecosystem around capability was required. But today, we’re seeing on a daily basis the need to understand unstructured data and catalog it, discover it, and understand what its role is within the organization. And there’s even more emphasis on things like the quality of the data, the lineage of the data, the compliance of the data access, the entitlement of the data, etc. You can almost draw a parallel of the entire stack that once existed on the structured side now needing to move to the unstructured side.
Building a typical pipeline requires real effort:
…all this, before it can be married to a model…and then you run into struggles like inspecting malicious prompts. So you also need a solution around exfiltration.
Audience Question: The idea of having a centralized mechanism for understanding what data we have (and making it simple to use and re-use) has been a bit of a holy grail in the information technology space for a long time, but we’ve never been able to achieve it because classifications generally break down the larger they get. However, we’ve been able to get by by doing just enough to make data accessible when and where it needs to be accessible, in order to protect privacy and so forth. So what’s unique about this moment in time that we need a data command center? And what makes it different from past efforts in the space?
A couple of things are coming together today. First is that people want to utilize this unstructured data in a very different way than they did in the past: to power LLMs. So a new need has definitely arisen.
You could say some of the same things about structured data in the past, but now with the vast understanding of language that LLMs bring, you can classify things in a much more high-efficacy way. However, you still need the metadata to be available. If it is though, you can build out a knowledge graph – which is a literal file-level understanding of where your data is. For example, if this is my audio file, tell me where it’s sitting, who is entitled to it, and what’s inside that file.
Generative AI is helping enable the ability to ask questions from these systems across any of the entities. Additionally, with new regulations popping up all the time, it’s becoming increasingly difficult to stay on top of data management in a piecemeal fashion. This is essentially a much stronger facilitator for enterprise search – except actionable against gen AI use cases (selecting data, protecting data, sanitizing data, and sending it to your LLMs).
Audience Question: A big trend we’ve all been seeing is the use of synthetic data – what’s your perspective on that?
Synthetic data is unquestionably used to replace structured data as part of your data pipeline. If you can replace your original data with a synthetic version, particularly on the structured side of things, mathematically, you can remove the unique tie back to the individuals. That’s useful. However, it’s not useful in many other situations where you still need to clean the data. Let’s say you have an audio file and within that audio file you want to know certain things, for example, that the audio file actually has very specific censored information at a single point in time that must be removed. You may need to apply different techniques to actually remove and redact this information. So it’s a very important part of your toolkit, but only applicable in certain situations.
Audience Question: What are the best practices for keeping AI models secure? What guardrails should be in place?
There are five steps organizations need to take in order to enable gen AI safely:
The future of AI is going to lie in enterprises being able to build, deploy, and manage intelligent AI agents. Generative AI as a whole is probably one of the most important enabling, and enabling is the operative word here, enterprise technologies in the last generation.
What we have to realize is that it is enabling technology, and that if we look forward, every company will need an intelligent agent to be able to capture this enabling technology and apply it within the enterprise (where it can create and capture value by taking advantage of enterprise capabilities required for managing and accessing data, and then leveraging that data through gen AI structures).
Intelligent agents will be how the enterprise interacts with their customers, their supply chain, their employees, and really even their products in the not-too-distant-future. So Sema4.ai’s focus is on how intelligent agents can get to a place where they’re delivering significant outcomes and enabling high ROI use cases at scale.
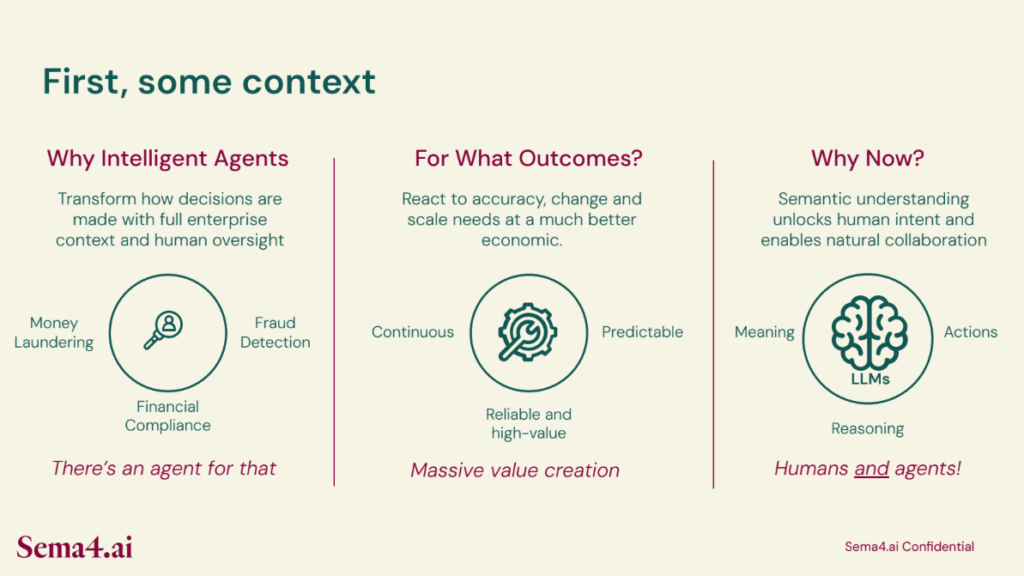
These agents are fundamentally different from LLMs or RAG applications, they’re very nuanced on how a user’s natural language queries are executed, they don’t just respond to prompts but actually provide the reasoning about and with full context of all the user’s needs (even anticipating what those needs are!). Then, they’re capable of determining the sequence of actions that they want to execute, based on short term working memory, but with an additional, longer-term repository of knowledge that comes from a runbook that Sema4.ai provides, and a gallery of use cases that reflect what human cognitive processes look like. Additionally, these agents provide the ability to leverage external tools and APIs that are truly required in order to execute complex tasks across both digital and physical environments, while leveraging both structured and unstructured data. This is going to be the unlock for massive value creation, making enterprises far more efficient.
Today, given where we are in this journey, the benefit for enterprise engagement on building, deploying, running and enabling these intelligent agents really comes down to achieving competitive advantage. But anyone can start small by an MVP success and continuing to iterate. It’s a good time to build a center of excellence around how to operationalize this muscle and create and measure the value capture and creation from it.
Example Use Case: Global Electrical Equipment Manufacturer, serving customers in 90 countries.
This company has a small team that performs a very interesting function today: monitoring a set of government websites for export compliance as the rules change around things like sanctions. Whenever they see that there’s a new update, they download the PDF, and this PDF is analyzed by their legal team. They come up with the deltas between their current policy and the government’s new policy (e.g. here are the new agencies and individuals who have been placed on the list), then they have to turn around and see if this actually impacts their business.
At this point, they need to go do some lookups in their backend systems to understand: is this a customer of ours? What kind of financial relationship do we have with them? Once they understand that, a new person (a combination of account management, sales ops, and legal) has to come up with a legal policy statement. Sometimes these could have ramifications, for example, if they’re a large customer who was associated with Russia last year. This will create a material change in revenue from that customer. So someone has to put this information together and send it all the way to the CFO’s office for them to review. These policy documents have very, very structured requirements, a template they must follow, and a review process they must go through. And at the end of all that, it’s only published internally.
This entire manual workflow can take 4-5 people a couple of weeks to get done. It’s very material and consequential for the business because if they get this wrong, not only do they have top line impact, but they also have legal and compliance impact that they could be exposed to. And then they get to do this all over again because the next update shows up every three weeks or so. This is an example of a workflow that humans are really good at, but if you take this workflow and deconstruct it, you can see that this involves having access to unstructured data that’s typically behind a paywall of some kind, being able to summarize and analyze that data according to a narrow set of guardrails established for performing this process, and then querying backend systems that are very structured themselves. Finally, the answers coming back from them must be used to create some unstructured content that goes through a document processing workflow, and then finally, you get your output.
Typically, the day in the life of someone who is doing this part of the workflow has a couple of downstream systems they’re taking action upon. The promise of agents is to convert workflows like these to short conversations. These are a few key elements that we’ve found very valuable when thinking about good initial use cases for agents:
These are the elements of a good use case. It brings all these kinds of attributes together and this hopefully gives you a sense of how you can go about considering which areas are amenable to this kind of cognitive or intelligent automation.
Audience Question: Do you have any real-world examples of the kinds of impact metrics you’re seeing? Whether that be efficiency, latency, consistency, quality, or something else? How are you measuring all that and what have you seen in the real world?
First, you want to define high ROI use cases that you can execute against quickly and efficiently. For example, instead of looking at point to point automation for invoice payment processing, where the current automation is either an ERP or an RPA, you want to think about how you can instead enable an end-to-end order to cash cycle where you can have many intelligent agents that are executing tens of thousands of invoices and HR engagement workflows. The key is the size and scale.
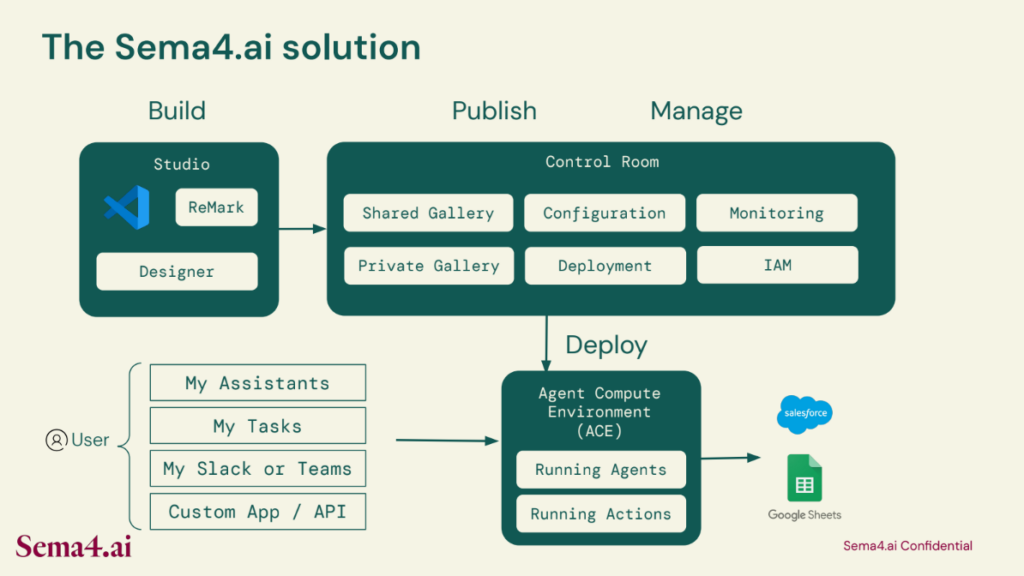
Sema4.ai today is providing customers with a runbook, or gallery, where these templates are available that you can either leverage and build upon (or you can bring your own new best practice standard operating procedure). This is all managed through the runbook with ample security, governance, and lineage standards. But this isn’t just about executing those automations, but also having the AI intelligence to remediate the changes in automation as conditions and events change or evolve. The goal is for the agents themselves to in fact help define what ROI efficiencies there are and where the most value capture lies.
Audience Question: From an interoperability standpoint, it almost sounds like we’re getting to a stage where agents are talking to agents or systems are talking to systems, and I’m very curious if you foresee this being a closed loop like, hey, we express intent our own way or we express the logic our own way, versus some sort of standardization on how it is actually expressed. Just like we have programming languages to express logic, correct? Do you foresee any sort of standardization there?
You have three really good points that you make. This is a really good perspective for us to take into account. All the parts of our cognitive architecture are natural language based, because we believe that that’s the best way to interact with agents. That’s also exactly the way we interact with humans today. So if you think of how our users interact with our agents and assistants, it’s through the messaging paradigm, through tasks like an inbox, through chat, through Slack and teams, and through APIs. This naturally leads to composability.
And so to your point, how does this language give you the flexibility of interoperability while also giving you the precision of knowing that you’re talking to the right domain agent? For example, you don’t want to ask a physics question to a travel agent. We believe that there will be a next level of higher order semantics schemas that will come into play here.When we were talking about the galleries of agents and the templates, these are all ways for us to start to publish metadata that helps us identify the agents that are appropriate for a given interaction. But we do believe that multi-agent is a composability problem, not a turn of the crank where you need to do something very different.
Today, you often see enterprises hesitate in front of the potential of new technologies, particularly open source technologies, like foundational models today vs. their deployment in production (at scale, on systems in the real world).
That has been the motivating factor for Vijil. My goal is to help infuse trust and safety into agents, as they’re being developed, rather than as an afterthought. And I agree that as this plays out over the long run, we do expect a world in which there are many different types of agents. There will certainly be agents personalized to individuals, as well as agents customized to large organizations. And most certainly they will be interacting with each other, although there will very likely be many intermediate agents that rest within the public sphere, some of which are actually quite well-behaved and normal, but there may be others that are antagonistic and hostile. We won’t be able to assume that the world in which the agents interact with one another will necessarily be a benign and friendly world.
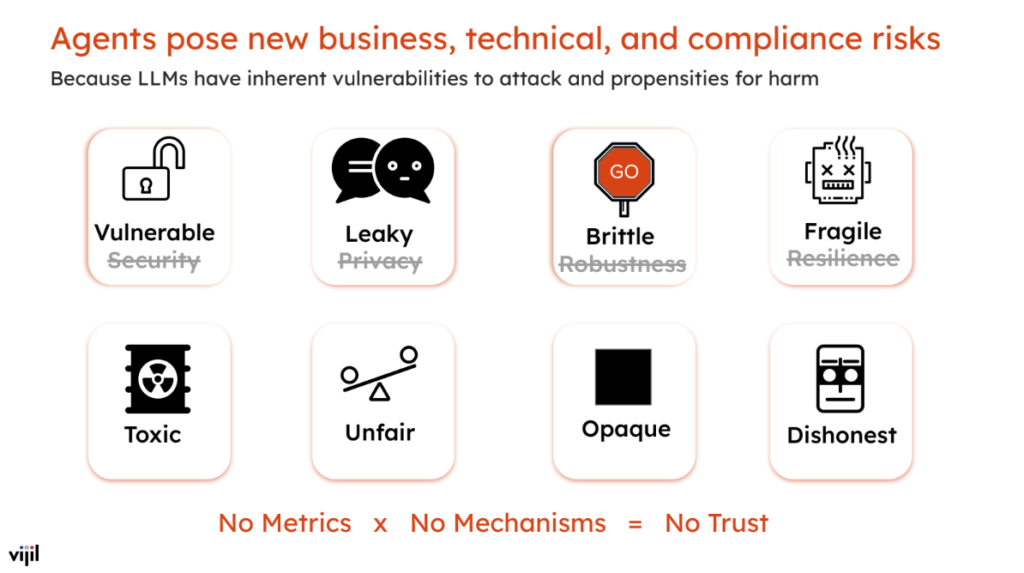
There will almost certainly be bad actors who build bots that are designed to be harmful to other agents and to other users. And so that’s part of how we see this world at Vijil. But even looking at today, before we get to that end state, there are still a variety of risks that must be addressed specifically at the model level. So I think in large part, one of the reasons why I have a particular take on this is that we see models as the first class citizens, and we plan to build on top of the data protection mechanisms that Rehan at Securiti.ai is building. But even if you’re focused specifically on the model, there are many different risks and lines of attack facing model developers today.
If you look at the history and the literature on the subject, there’s a ton of work on many potential ways of attacking ML systems, ML models, and the data that drives them. And now it’s true for LLMs as well. We’ve looked at the full taxonomy of attacks and possible ways in which these models can be compromised. But ultimately, we see today’s approaches around the state of the art for LLM security and safety to be focused on this inbound vector of prompts and prompt injections, with the response being to block and filter them through LLM firewalls or guardrails that prevent harmful outputs from going back out to the end user.
Perhaps some amount of alignment based on reinforcement learning with human feedback can put a friendly face in front of this kind of vast LLM behemoth. But underneath the hood is a monstrous entity that has been trained across the entire internet, for better or for worse, to produce whatever it is that it produces. This isn’t an area where we see as much attention being paid fundamentally to the nature of the model itself.
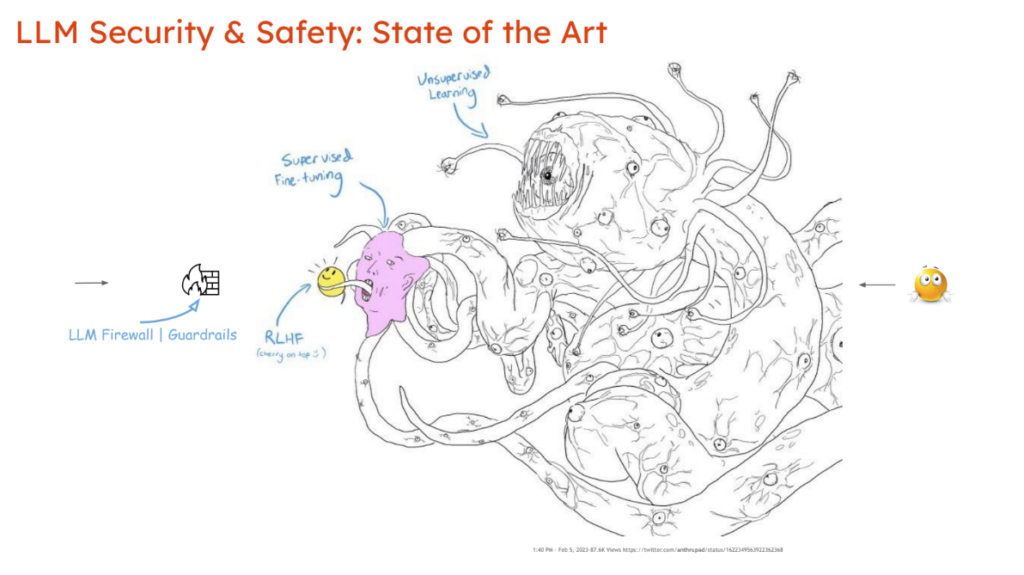
And that’s why we think that the way to approach this should be two-pronged. Certainly the approach of finding vulnerabilities to attack within models and detecting propensities for harm via some kind of an evaluation or scanning mechanism is important. Our approach is a red team and a blue team that work together to find and fix vulnerabilities and other negative propensities on a continuous basis, constantly adapting to new attacks. This must be done fast enough as to where it doesn’t block the model developers and the agent developers from deploying their models into production.
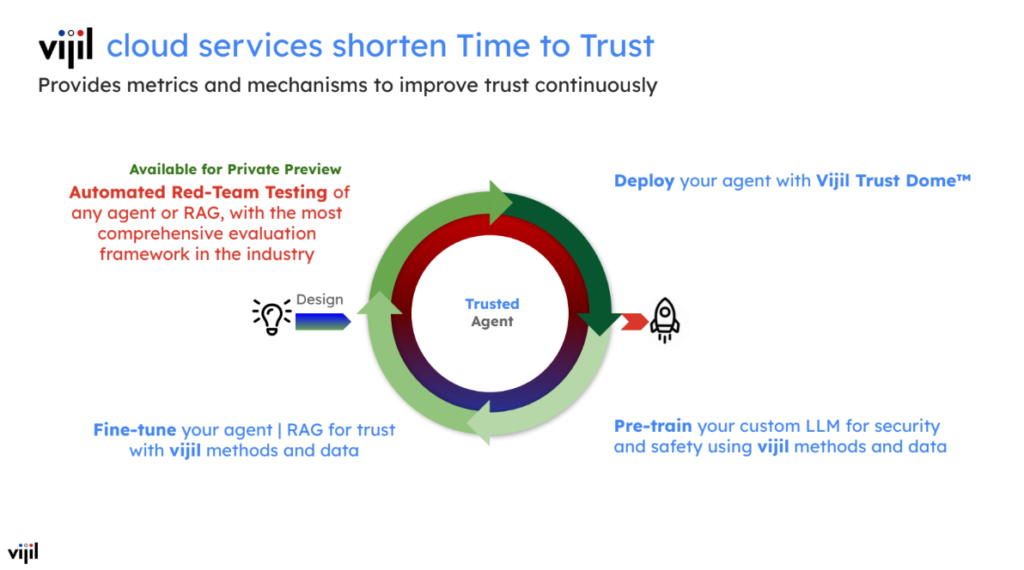
The way we built processes like this into the AWS AI organization, where I led the deep learning team, was to really bake in the classic “shift left” of security into the development process for AI and ML development. And you’ve seen trends or movements like ML SecOps reflect that position. But in some ways, I think even with ML SecOps, it feels like the point of insertion is reflected in the name, and the security should go even further left into the design to the development of the model itself. And so we see this coupling of the red team and the blue team as something that you bake into the agent and the model development process. And so what we started out with was just this fundamental idea that you can’t improve what you cannot measure. So you have to first measure trustworthiness. And today trustworthiness is barely well-defined, let alone measurable.
So we started out by building metrics and putting together an evaluation framework that lets you measure the trustworthiness of an agent, RAG application, or the model specifically inside it, with the capacity to test this at scale, quickly, so that it doesn’t interrupt your development workflow. Step two is creating a holistic envelope that protects the model and agent from both inbound and outbound issues. The final result of this analysis and evaluation generates a trust report and score for that LLM or agent – similar to how credit scores work on the individual level. It has eight dimensions today, and is coupled to performance so that the model or agent’s competence is tested as well (ultimately, these are some of the trade-offs we often see developers make in practice). If you improve the robustness, for example, it’s possible that when you train the model, the robustness may improve, but its accuracy may be reduced. So, the balance of these eight dimensions must be taken into consideration while developing a high competency model.
Audience Question: Is the scoring dependent on the use case itself? Or can you have one trust score that applies across all use cases?
I don’t think there will ever be a situation where you’re done with the evaluation. That being said, I do think that individual evaluations can be extended and customized. They’re frequently use case specific, although there are some common patterns across model architectures and model types. For example, you could start with a set of common goals that attackers might have when trying to disrupt the operation of an agent or a model. So you can identify a hundred or so of these goals and they’re fairly use case agnostic. We should be testing for these types of potential attacks from any source under any condition.
But when you look at more specific use cases, perhaps a bank chatbot, the bot in this case is representing a customer service agent that has access to a backend database, and perhaps isn’t enabled to write to the database, but can certainly read from it. So you’d want to ensure that it represents the organization’s policies and standards for customer interaction, that it protects the organization’s brand identity, that it’s not recommending other brands for simple questions, and that it doesn’t disclose personally identifiable information. So there’s a bunch of things that are unique to what a bank chatbot does. That would mean that the evaluation of the bank chatbot is highly customized, but at the same time as an agent, as an LLM model, I think it’s vulnerable to a number of different attacks and you would do a broad range evaluation for that purpose.
Audience Question: How do you weigh the various elements in the model? What’s the math behind that and how is that controlled? I assume as you progress your business and get into the really large enterprises, you’d have an entire policy driven governance model so that corporate admins could skew things towards one of the eight elements from a weighting standpoint? Is that the direction you’re going?
That’s exactly right. We already do this today. We have a weighted means. So right now, the weights upon shipment are equal. But we expect our customers to adapt and modify things for their own use case valuation frameworks.
Audience Question: How do you establish trust in the trust core? Why you, and why your sources of explainability?
The report itself and the measures that we use, as well as the individual prompts that produce the particular responses, and the evaluations, are publicly available to our customers. So we’re transparent in the evaluation process. That’s not where we’re withholding IP.
The core of where we see Vijil evolving is in building blue team capabilities that fix those issues, which we think is the much harder problem. Almost every paper on adversarial machine learning today is about finding the upper bound of attack vectors that you can assault a model with. There’s much less out there about building systems that can defend the model in-depth or build in-depth defense mechanisms more specifically. So that’s what we’re focusing on. We’re happy to share the specifics of how the model is evaluated and adapt it as we go along.
