

80% & 50%
Enterprise cloud computing has evolved faster than anyone could have foreseen just a few short years ago. According to Rightscale’s 2018 State of the Cloud Report, eighty percent of large enterprises now have a multi-cloud strategy. Fifty percent are packaging apps in containers, allowing apps to move easily between cloud platforms, and the number of organizations using serverless computing has nearly doubled. The next step in the evolution: adopting a cloud native approach to app development.
For our previous CIO Insights session, we asked Vivek Saraswat to take us on a deep dive into mastering the complexities of multi-cloud architecture. In part two of that discussion, Vivek brings us along on the journey to becoming cloud native. He is joined by two special guests from Mayfield portfolio companies: Dave McJannet, CEO of HashiCorp, a leader in cloud infrastructure automation; and Eric Han, VP of product management at Portworx, a secure storage and data management platform for cloud native applications. Our speakers also addressed several probing questions from our distinguished panel of CIOs.
Key Takeaways
Being cloud native is about abstracting infrastructure workflows from application development
- Cloud-native’s foundational principles are scalable apps, resilient architectures, and ability to make frequent changes
- Key technologies include containers, microservices, and dynamic orchestration
- Current major challenges include identifying the right tools, modernizing legacy apps, and standardizing workflows across clouds
- Becoming cloud native is a journey, not a destination. There are multiple steps a company can take to begin and progress on this journey.
What ‘Cloud Native’ Really Means
Over the past several decades we’ve seen a tectonic shift in the way applications are developed – from monolithic mainframe apps, through client-server, and on to web servers and mobile applications. Now we’re moving into the cloud native era.
What does that actually mean? We think Matt Klein, co-creator of Envoy and a senior engineering leader at Lyft, said it best: “Cloud native is how we abstract infrastructure from application development.” In other words, we now see a near-total divide between physical or virtualized infrastructure and all the components that support the application – networking, storage, routing, and the apps themselves.

The Cloud Native Computing Foundation’s definition is more expansive: scalable apps that work across different types of clouds, with loosely coupled but highly resilient systems that can be managed automatically. When people talk about continuous integration and continuous delivery (CI/CD), or Google talks about site reliability engineering, this is really what they mean. It’s about the ability to make frequent changes to a system with minimal effort.
This definition rests on three key concepts:
- Packaging applications inside containers, which allow you to quickly spin up apps and run them in different environments without having to worry about dependencies and changes.
- Loosely coupled microservices, which talk to each other via an API and serve the user across multiple dimensions. You can have several independent microservices, some of them identical versions of each other, so that if one goes down another can quickly be put in its place.
- Dynamic orchestration. If you’re scheduling microservices across multiple nodes in a cluster, orchestration is the brain that controls how those apps are scheduled.
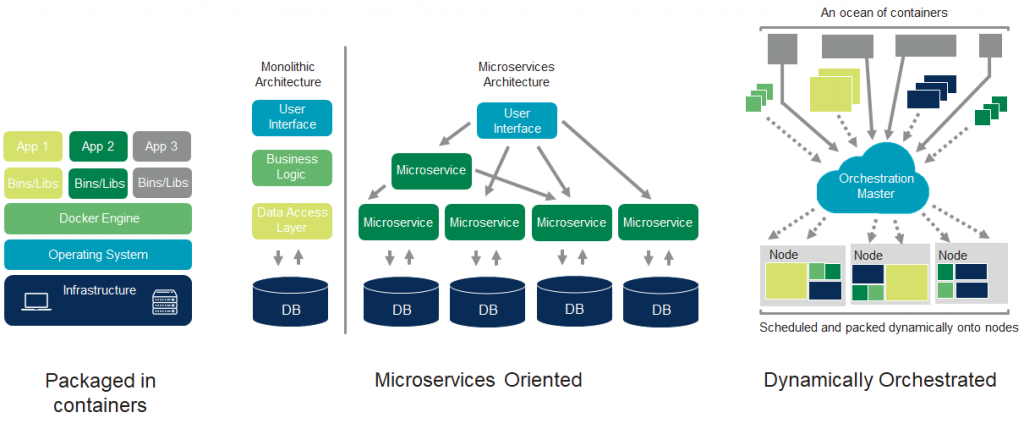
Today roughly half of enterprise organizations are running containers, and about a quarter of them use Kubernetes orchestration. But what’s really interesting is serverless computing, which allows you to run apps without ever worrying about the underlying infrastructure – growing 75 percent year over year in the enterprise. It’s a clear sign that people are really interested in how to abstract app development and deployment from infrastructure. We’re going to see more of this as time goes on.
Three Key Cloud-Native Challenges
There are three significant challenges enterprises must overcome before they can go cloud native. The first is selecting the right tools to match their workflows. Another is legacy apps. It’s relatively easy to build greenfield apps that are cloud native; modernizing legacy technologies is much tougher. The final challenge is making processes work across a multi-cloud environment — something we talked about in depth during our last CIO Insights call.
Over the last two years the number of cloud native tools has increased by an order of magnitude. Following all of these companies across every area is nearly impossible.
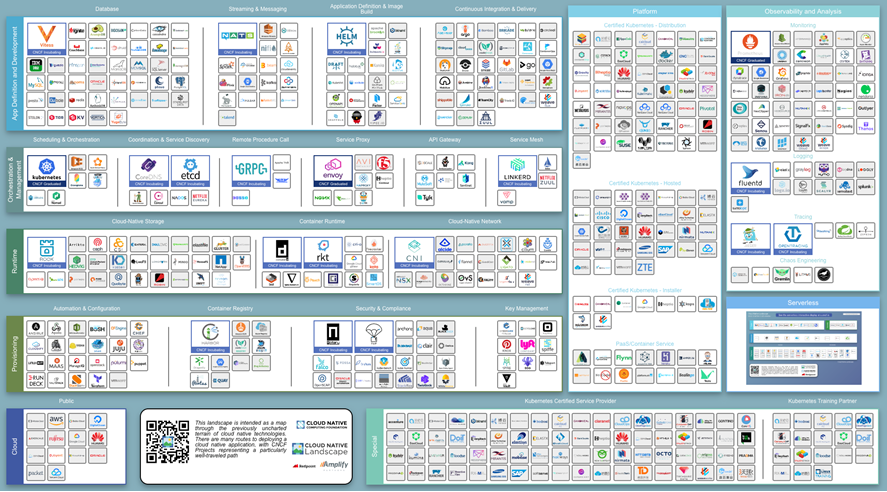
To figure out which tools to use, enterprises need to identify their key workflows and find tools that fit each use case. It’s better to select a purpose-based tool for a specific workflow than to choose a Swiss Army Knife that can do a number of things. You should also pick tools that are standardized, battle tested to operate at scale, and can work across multiple infrastructure and environments.
At KubeCon last December, Jasmine James, one of the DevOps leaders at Delta Airlines, offered up a really neat framework for finding tools that match your workflows.

As she notes above, you should look for tools that applicable to your environment and enterprise ready. They need to have robust APIs that allow them to integrate easily with other tools, not cause excessive overhead for your dev or ops teams, and have easy-to-use workflows that can be adopted across teams to encourage collaboration. Most important, they need to be useful in solving an actual problem.
Modernizing legacy apps is a bit trickier. You need to approach this problem gradually. You can containerize parts or all of an existing application without adopting a microservices architecture. From there you can slowly integrate modern methodologies like CI/CD, automation, and observability, piece by piece. At a certain point, you’re either adding new microservices on top of the existing legacy service, or you’re killing off services from the monolithic codebase.
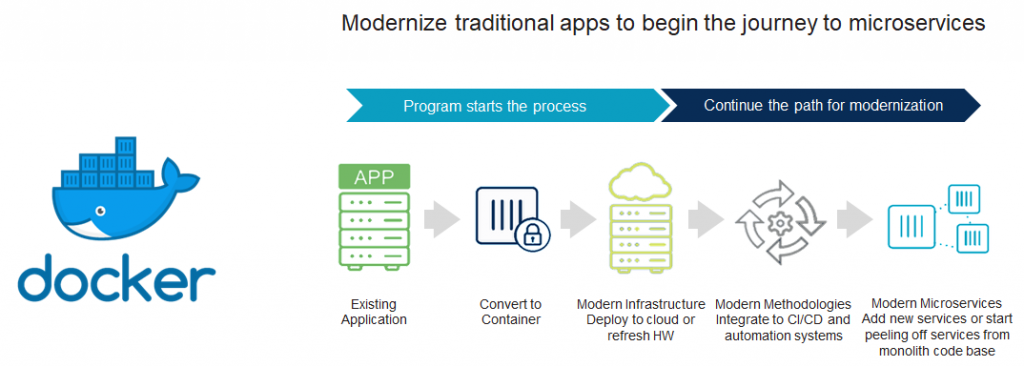
The key thing to remember is that you don’t have to fix everything about your legacy application all at once. You can build new services on top of it and make more changes over time as needed.
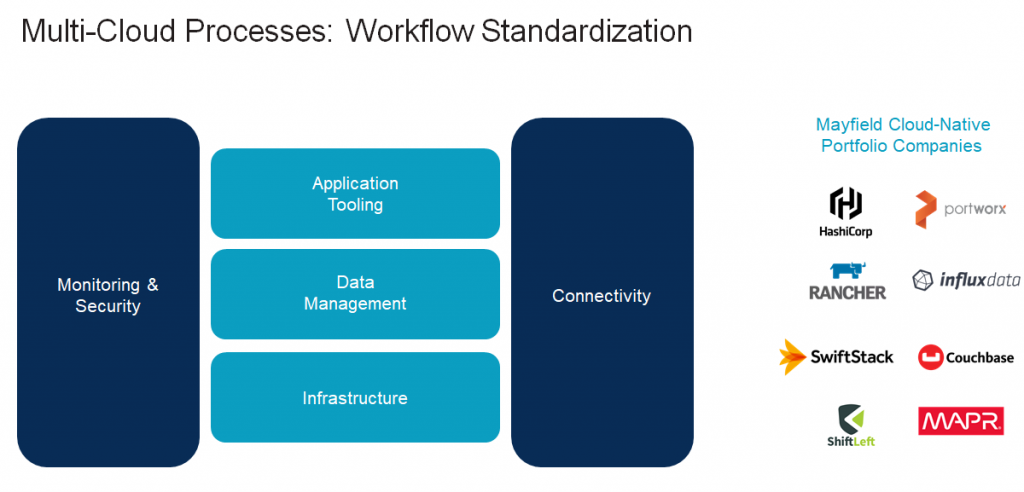
Finally, there’s the challenge of building across multiple clouds. The key is creating a strong set of workflows around a base infrastructure you can standardize across different environments. There are a few components to this. You’ll need to make sure your data is standardized within your existing clusters and can move easily between clouds. You’ll need a standard way to build applications. You’ll need to implement monitoring and security throughout the stack, and you’ll need connectivity between applications at each level.
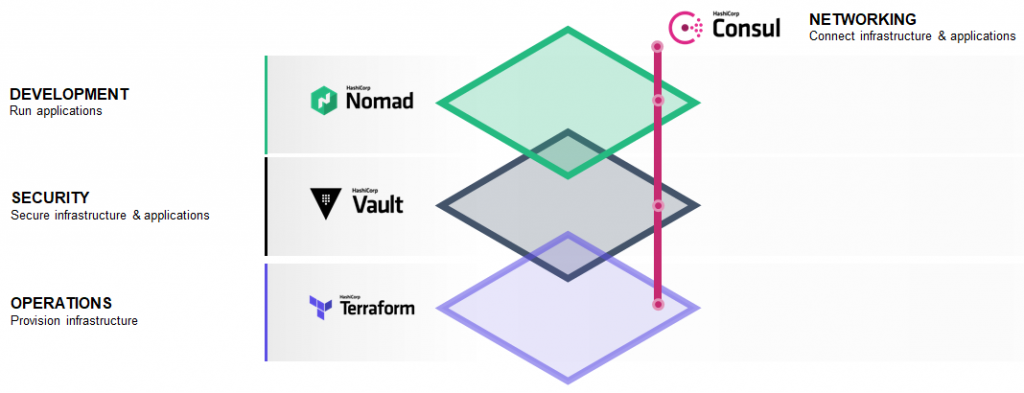
HashiCorp’s Dave McJannet on Cloud Infrastructure Automation
We now live in a multicloud world. Even organizations that still maintain their systems of record on premise are using the cloud to build and deliver new apps. That’s because cloud-native apps are more elastic, engaging, and can be delivered more quickly.
But going cloud-native changes how enterprises provision infrastructure. We’re moving to an on-demand world where an organization may spin up 200,000 compute nodes on one cloud for a short period of time, then spin up another 200,000 on a different cloud. That also has implications for app security. Instead of running inside the perimeter of a network, where it can be assumed that any database requests coming from a certain IP range can be trusted, apps are running on a low-trust network in the cloud. So the shift in the cloud-native world is to security built around identity.

There’s an equally profound shift at the network level, away from static IP-based devices and towards a dynamic service-based system that says ‘this is a database, this is an app server, they can talk to each other.’ And at the very top layer, you’ll need to accommodate a wide range of different application types — Kubernetes, Cloud Foundry, Java, Hadoop, and so on.
In short, going cloud native means re-examining your entire approach to infrastructure, security, networking, and runtime apps. You can no longer use vCenter to provision infrastructure, because you’re provisioning compute on Amazon and Azure. You can’t use firewalls because they make no sense in a cloud-based container world where IP addresses are constantly changing.
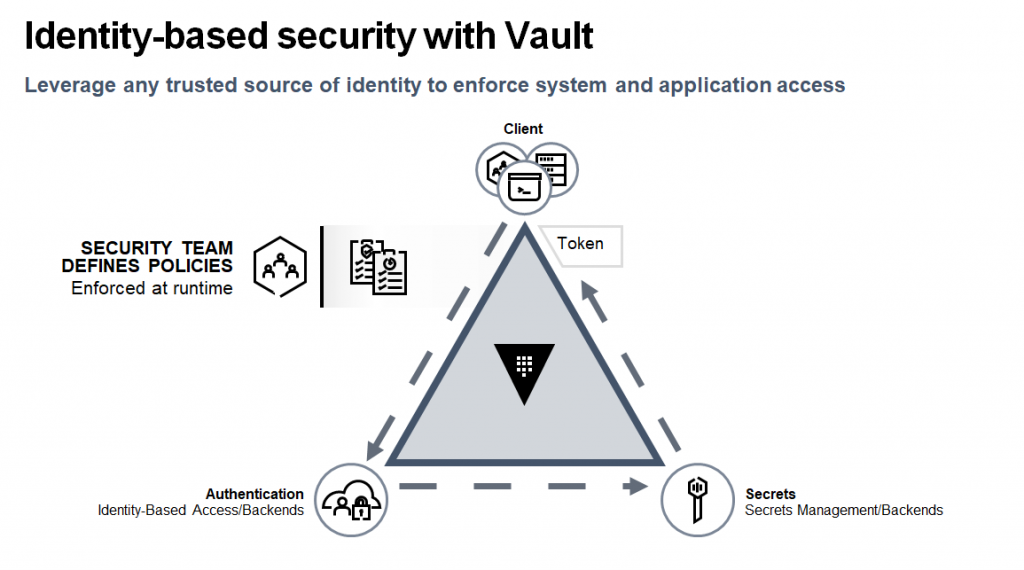
HashiCorp makes open-source products that address each of these layers, but let’s look at security as one example. The HashiCorp Vault product is used by nearly all of the Fortune 500 to manage identities in the cloud. When an app running inside a container makes a request to an on-prem database, Vault authenticates the identity of the requestor, then provides a temporary password to that backend system. The client never has the database user name and password; all it knows is where to find Vault to make the request.
Your security team determines how often the password token needs to be refreshed — once every 10 minutes, once a year, or somewhere in between. The log in credentials are never stored in the source code and never shared. There are also more sophisticated things you can do, like turning on encryption for everything in that workflows. But having a central service that all of an enterprise’s dev teams can share is the key to securing secrets in the cloud.
Portworx’s Eric Han on Unlocking the Cloud Native Platform
When working with microservices, the notion of right sizing is no longer relevant. You need to deploy based on intent, you need elasticity, and you should let your application teams pick the apps they want to build. And thanks to automation, you can get much more responsive and often more personalized results. The ultimate goals are simplicity, agility, and adoption.
But adoption has been held back by the inability to handle stateful data-rich applications, such as SQL databases. This is where Portworx comes in. At a technical level, Portworx is a form of virtualized storage that leverages existing infrastructure. We integrate with schedulers to automate storage provisioning and allow stateful applications to be portable across multiple stateless environments.
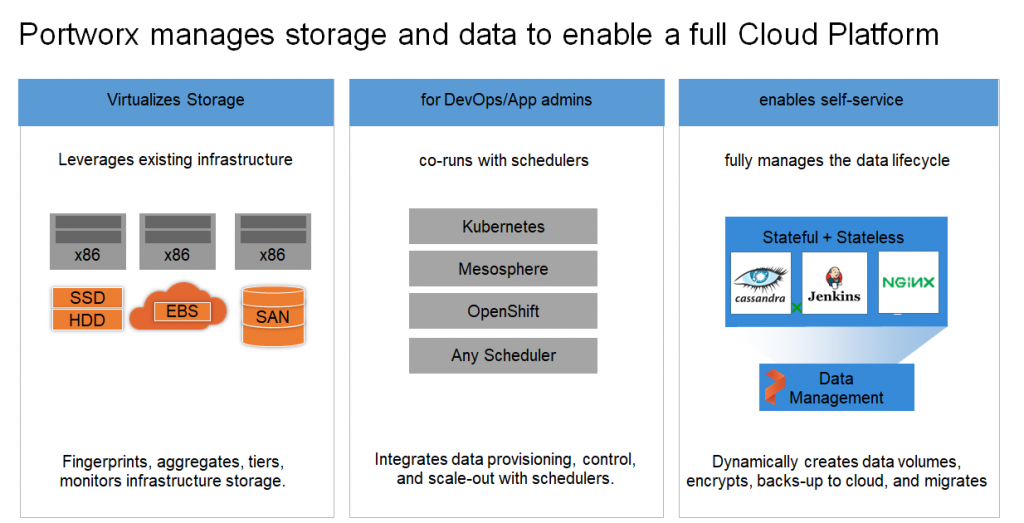
If you want to run a mission-critical database across any infrastructure, you need a control signal that lets you put it near where the data is stored. You want to do it quickly and securely, and make it a centralized control you can run across hundreds or thousands of servers. That’s just one of the things Portworx does.
It’s really about simplifying infrastructure. Going cloud native means enterprises no longer need to think about what hardware they’re buying; they just need to think about what the application requires. Portworx is the layer between the infrastructure and the application that lets them do that.
If you look at how people are using HashiCorp’s Vault, it’s a set of workflows that build on top of one another to allow for authentication. And with Portworx, you have people starting with stateless apps and trying to build out stateful apps to increase their adoption.
The key concept to take away is that there is no one ideal end state where you end up saying “this is how a cloud native application should be.” Getting to cloud native is very much a journey, a series of trends along the path of migration.
Input & Questions from the CIO Panel
How do you integrate existing SaaS apps into cloud native orchestration?
That’s an extremely important component of this. Most of these cloud-native tools are built across a well-communicated Rest API, gRPC, or something similar. You need to make sure that the SaaS app has a comprehensive Rest API and/or use a separate integration tool like Zapier. This goes back to being purposed based. The SaaS application may not be built as a communication tool, but you can use other SaaS integrations to ensure that you’re connecting the application to your existing infrastructure.
Moving to the cloud can also mean re-engineering a company’s financials. How should they handle that?
We’ve seen a lot of companies struggle with the transition from capex to opex. There’s no easy answer to that. Most of the organizations we’ve seen make a strong transition to working with AWS, Azure, or Google Cloud want all of their services to be opex. We’ve seen more and more companies move towards a consumption model for CPU cycles, memory, and storage. Even in their on-prem environments, they’ve started adding charge-back tools for consumption-based work across their various departments.
How can CIOs persuade the business to adopt microservices and serverless computing?
That’s a great question. In many tech-forward organizations it’s the engineers who are pushing this shift toward microservices and serverless. But most enterprises don’t work that way. In most scenarios, the CIO can provide frameworks that dev teams can use. Some of our portfolio companies, like Rancher, provide tools and application templates that let you put guardrails around how an engineering team builds its first microservices application.
You might have a hundred business groups who need to create applications that live in the cloud. How do you unlock that velocity without giving up control? Then there are questions around how you address security, provisioning, and networking. A big part of it is building workflows you can easily share across various teams, whether they’re line of business units, IT, AppOps, or SecOpps. And because it is a culture change, it helps to identify a champion, someone who can pick up the ball and carry it across the goal line.