

The cloud has become the dominant computing paradigm for enterprises today, and rarely just one cloud. IDC has predicted that 85 percent of enterprise IT organizations will be running a multi-cloud architecture by the end of 2018.
While relying on solutions from multiple cloud providers can provide flexibility and speed the pace of innovation, it also introduces complexity and raises serious concerns about security, risk, and cost management.
To discuss the key challenges of multi-cloud, we invited Vivek Saraswat, former product leader at Docker, to host our October Mayfield CIO Insights session. He was joined by two special guests from Mayfield portfolio companies: Shannon Williams, co-founder and VP of Sales at Rancher, and Tom Fisher, CTO of MapR Technologies. As part of the discussion they answered probing questions from our distinguished panel of CIOs.
In the not-so-distant past, most of us were running on-premise systems such as VMware vSphere, IBM Weblogic servers, Oracle databases. There was a big divide where primary applications ran on-prem, and the cloud was used primarily for native SaaS applications and remote backup. There was strong resistance to migrating applications to the cloud, as many orgs were unable or unwilling to do so.
Today, most organizations are running a hybrid cloud environment: a private cloud on-prem and at least one public cloud, whether it’s AWS, Azure, or GCP. Many mission critical applications and sensitive customer data still remain on prem, and the cloud gets used more for greenfield apps. Cloud migration issues have been partially solved using containers, due to the ability to write code once and run it anywhere. I say ‘partially’ because, if you run an app in multiple environments, you may still have problems making sure the data tracks along with it.
When we talk with IT organizations, a key concern with the public cloud is vendor lock-in. Once you start building applications in AWS using the EC2 API, it’s not very easy to build processes outside of that framework. Data privacy is also an issue. With the rise of GDPR and recent data breaches, people are concerned about whether data in the cloud is secure, whether from malicious actors or potential competitors.
All of this provides the basis for why enterprise IT organizations are choosing a multi-cloud architecture. The primary reason is avoiding vendor lock in. Another is price optimization – enterprises want the ability to pick cloud solutions based on cost. And a third is that due to fragmentation and M&A, different IT groups in a company may have different cloud platforms, and it’s difficult to move workloads and processes from one cloud to another.
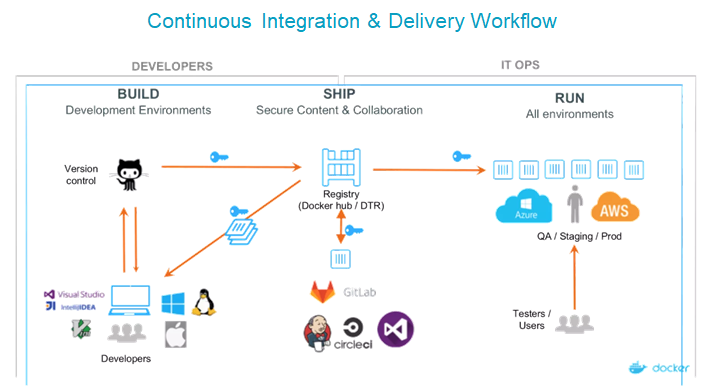
Having a standardized, unified pipeline that works across different environments ensures that you’re not locked into AWS, Azure, or on prem, and you can move your code more quickly from each step to the next. At Docker we used a framework called “build, ship, and run.” Developers run on their local environment of choice, and push through code to a source control platform like GitHub. That code gets built into artifacts called Docker Images which are stored in a central registry. Each time you push new updates to the version control platform you create a new image artifact via continuous integration. So instead of doing large software updates, you’re pushing minute bits of code at regular intervals. Using a continuous delivery tool you can automatically deliver the application updates to clusters either on-prem or in the cloud.
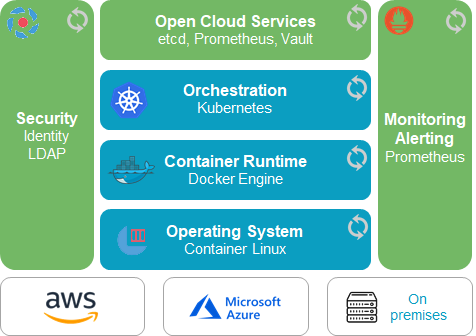
One key challenge in multi-cloud is figuring out how to standardize application management and cluster management across various environments. Alongside containers as the standardize application format of choice, you need a unified orchestrator managing both clusters and applications—Kubernetes is the platform of choice for this. You also need a standardized software delivery process like Jenkins for CI and Spinnaker for CD, and production-grade monitoring/logging tools like Prometheus and Influx. All of these need to work across dev/test/prod environments, in both public and private clouds, and by both developer and IT Ops users.

Another key challenge we see is around managing and migrating stateful data across clouds. Scheduling applications is cheap, but moving data is expensive. How do you ensure that the data and the app are co-located correctly, and how do you match the correct storage to the use case? No matter what type of cloud you use, having the right kind of storage is essential. This is a huge problem in a single cluster environment; as you move into multi-cloud it becomes an order of magnitude more difficult.
When we have conversations with customers we discover that the innovation isn’t necessarily happening in the IT department, it’s happening on the application delivery side, as teams embrace CI/CD to solve a specific problem. Whether it’s an insurance, service, or media company, they’re all implementing CI/CD or microservices to allow teams to modify and change components without necessarily rebuilding the whole system.
A common scenario is where one team rolls these out on a predefined set of infrastructure. But containers, microservices, and CI/CD are like the measles – they spread pretty quickly from one team to another. All of a sudden you see lots of lots of organizational groups running Kubernetes on different infrastructure, depending on what they’re trying to do.
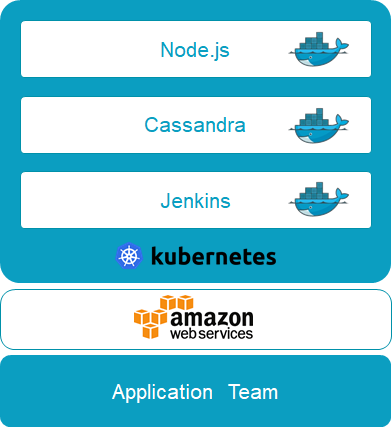
It’s not multi-cloud for any of these groups by themselves, but it’s become multi-cloud for the organization, as different teams choose the infrastructure they need in order to innovate. It’s like when VMware started and we saw VM sprawl, before it became clear to IT that this was something they needed to manage.
As this technology spreads, you end up with a lot of application teams managing a lot of infrastructure. That isn’t always good, because application teams tend to have a high turnover rate. The most common call I get is from companies where the person who built the Rancher environment has left and they no longer know how to run it. I can often say, well, you have three other groups in your organization running Rancher, maybe you guys can work together and start managing this as a central platform. This is where IT can help. You want to give these application teams as much room as possible to innovate and make it easy to do, but you also want to centralize critical pieces such as security, policy, user, and cost management.

Disney is a good example of this. They embraced containers early on to solve multi-cloud and gave their developer teams a choice: Let IT run Kubernetes for them, managing policies but giving teams control over the applications; or allow them to manage their own Kubernetes environment, which IT would set up, ensuring that they tied into Disney’s global infrastructure, and cost management policies.
Disney now has more than 60 production apps running in Kubernetes clusters with dramatically better density. They’ve seen a 40 percent savings on their Amazon bill alone, simply by taking underutilized VMs and consolidating them into clusters, allocating namespaces to teams so they can aggregate consumption across different workloads. They’ve also increased the incentive to innovate by making it easy to spin up different types of data services.
MapR’s goal is to expand app portability to data. Our primary use cases revolve around AI, machine learning, and analytics. The product is designed for a multi-cloud environment and is really focused on container persistence and deployment. We’re also really focused on expanding this analytic capability out to edge devices, which has become really critical for our customers in the oil and gas industries.
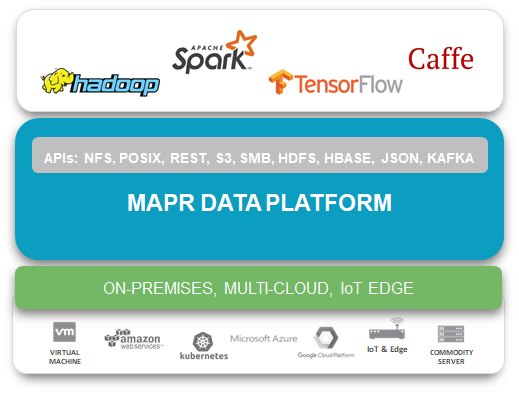
As others have already discussed, you’re always going to have some kind of lock in. That’s why we focus on how to run this stuff out of the box using data access standards like NFS and POSIX. We support industry standard APIs, like HDFS or Kafka, that let you manage data regardless of where it is or what form it’s in, as well as operational apps using HBase or JSON. At the end of the day our goal is to really manage multi-cloud.
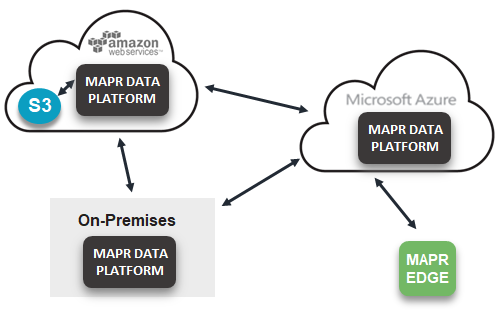
Data movement is an enormous problem. Clouds are all a bit different, so if you claim to be multi-cloud you need to support the different capabilities within each of them. We’ve built native integrations with all the clouds; we support the APIs for Amazon S3, which Google and Oracle have adopted, as well as outliers like Azure’s. In addition, you need to connect to on-prem legacy environments so you can leverage capabilities like data mirroring and replication. And you have to incorporate that into the edge, which is increasingly becoming the way the cloud is distributed.
We believe cross-cloud platforms will only be enabled through data APIs. MapR includes a global namespace across all tiers which allows for that. Customers are always looking for the best places to put their data; we use machine learning to look at their data use patterns and identify the optimal places to store it. That’s something you need to consider when looking at the cloud, because there’s extremely expensive storage, and low-cost options like Amazon Glacier. Applications need to be smart enough to make a single call to get that data, and platforms need to be smart enough to get that data no matter where it’s stored.
To sum up, multi-cloud is definitely a priority strategy. It’s something we’re hearing from the startups and the customers we talk with. As we’ve noted, the primary drivers are the desire to avoid lock in, the ability to shop for the best price, and the need for a broader range of technology solutions.
Having applications and data structures that are agnostic from individual clouds is the key to making multi-cloud possible. That means focusing on open source technologies such as Kubernetes and containers, so you can switch between providers more easily. The more you focus on providing cloud agnostic and unified pipelines, even if you end up using only one public cloud at any time, the better off you’ll be.
The RightScale State of the Cloud 2018 Report showed the most important consideration for companies operating in the cloud is cost optimization. It’s very easy to keep spinning up new resources within AWS and Azure. Many people have EC2 instances running at partial capacity or no capacity at all, taking up OpEx spend. When I was at Docker, we often had to deal with “zombie VMs” running in the cloud and taking up additional cost.
One solution is containers, which make it easy to spin up or down resources as necessary. It’s easier to ensure that once you’re done running an application or a process you’re no longer paying for it. There’s also a new class of startups focused on how to handle cost optimization within a single cloud as well as multiple clouds.
Network security has gotten harder in the microservices world. In the old way of doing things, you had an application firewall around the perimeter, which offered a decent amount of protection. As we moved to a VM to VM world, we started seeing micro-segmentation, which provides virtual boundaries between applications. With microservice containers and multi-cloud the boundaries have become a lot more porous. It’s more difficult to see the connections between different applications where malicious actors might strike; the attack surfaces become a lot wider.
So, we’re seeing companies move away from a perimeter model that relies upon a blacklist for different services, and adopt a white list model where only specific behaviors are allowed. That could be a list of behaviors defined by the organization’s compliance policies, or a probabilistic analysis that analyzes your environment and the connections between various services, then builds a set of policies to detect threats and remediate them.
To a certain degree, you’re always locked into something. But if you’re running multiple clouds, you have the potential to optimize your costs between them which is a form of mitigation. We’re also seeing increasing reliance on open source technologies and companies that support this. One example is Spinnaker, a Netflix technology that makes it easy to push application updates to different environments. I know a few companies that are already building solutions based on Spinnaker. If you build your technology against an open source API, you can find companies that support it, which may provide the ability to switch to others that support the same API. Your processes remain in place, but you can avoid lock in from a specific commercial vendor.