

For the last eight years, Amazon Web Services has been using its annual re:Invent conference to showcase new cloud products, services, and partnerships. We’ve attended the conference for the last several years and are impressed by how it continues to grow in size, scale, and ambition.
At last December’s re:Invent, AWS made 53 major announcements in areas ranging from analytics and machine learning to quantum computing. Even the savviest CIO would be challenged to fully digest all of that information and place it into the proper context.
That’s why for our most recent CIO Insights call we invited AWS’s Worldwide Head of Business Development Ian Swanson and AWS Principal Solutions Architect Paul Underwood to break down the key learnings from re:Invent 2019. These are the innovations in machine learning, microservices, and hybrid cloud that technology leaders should pay closer attention to in 2020.
At AWS our mission is to put machine learning in the hands of all developers at all organizations, no matter their size or industry. Machine learning is how our customers derive value from their data, which is driving digital transformation across the board. Tens of thousands of companies use our ML solutions because we offer the broadest, most complete set of capabilities across the AWS ML Stack.
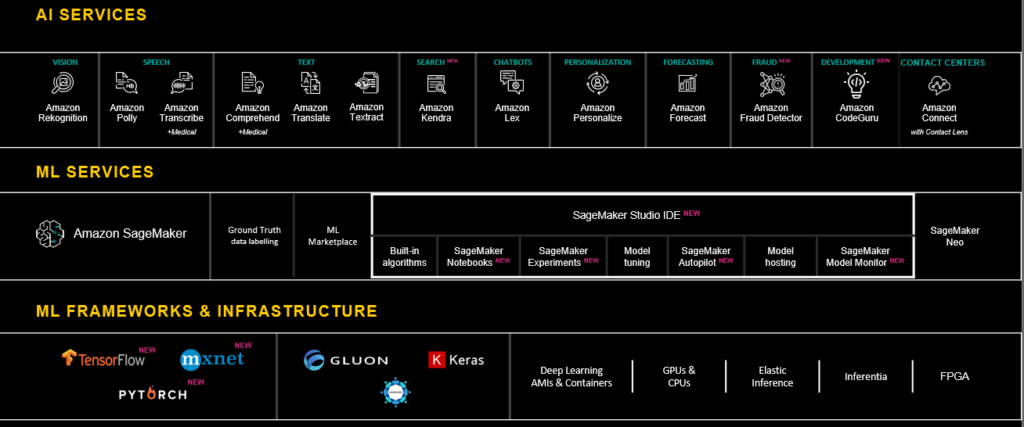
On the bottom layer are frameworks and infrastructure — the tools that make ML work. In the middle there’s ML services, which data scientists and engineers can use to build, deploy, and monitor applications. At the top are AI services: pre-trained models that can add intelligence to any application, such as image recognition, natural language processing, or forecasting.
But deploying ML in the enterprise still faces common challenges. There’s a skills gap – not enough people know how to build the models. It’s time consuming and complex. Building a machine learning model involves dozens of tools and hundreds of iterations. The lack of integration becomes a huge drag on productivity, increasing the time and cost of getting applications into production. And identifying the right business use cases for ML isn’t always easy.
At re:Invent we introduced several tools to make ML easier to build, scale, and deploy.
Amazon SageMaker Studio is the first fully integrated development environment (IDE) for machine learning. Studio sits on top of the infrastructure stack, making it simple for data scientists to build, train, deploy, and manage models. The single-pane-of-glass view allows them to manage the entire workflow in one place.
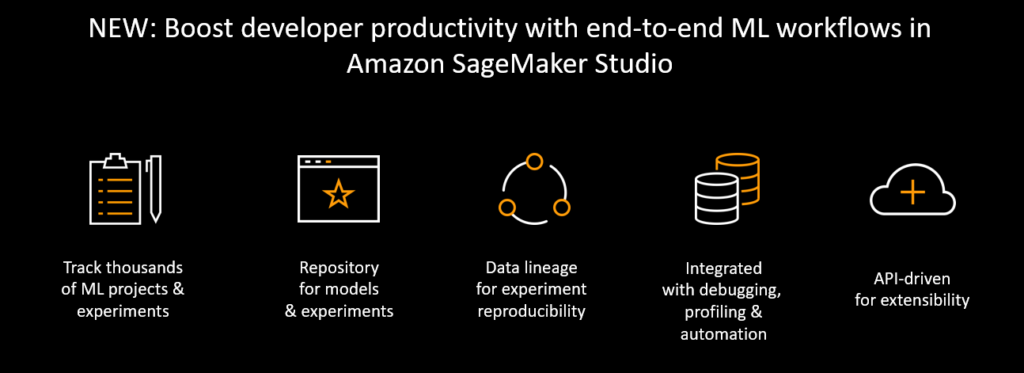
Data science done right is truly a team sport. But the tools currently in the market don’t make it easy to work together. Data science needs to be shared, reproducible, and easy for IT to manage controls and permissions. We’ve made that super simple to do with SageMaker Notebooks.
Data scientists create hundreds of experiments, each with multiple parameters. To choose the right ML models they need to compare results between experiments. SageMaker Experiments lets ML engineers store literally thousands of experiments in a single repository and track them all in one place using APIs.
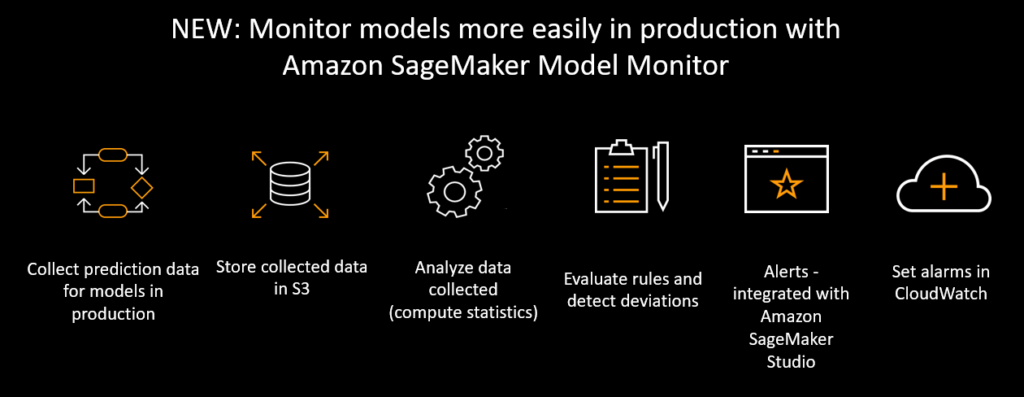
Many organizations think that once they’ve developed a particular model their work is done. But as people and systems interact with a model, the data can drift, making the model less reliable. That’s why AWS introduced Model Monitor, which can collect and analyze performance data and set up alerts to warn when a model is becoming less accurate over time.
As noted earlier, building models can be very complex, and organizations don’t always have enough skilled personnel make it happen. SageMaker Autopilot automates basic code production in order to shrink the skills gap and reduce the time data scientists spend building and exploring models.
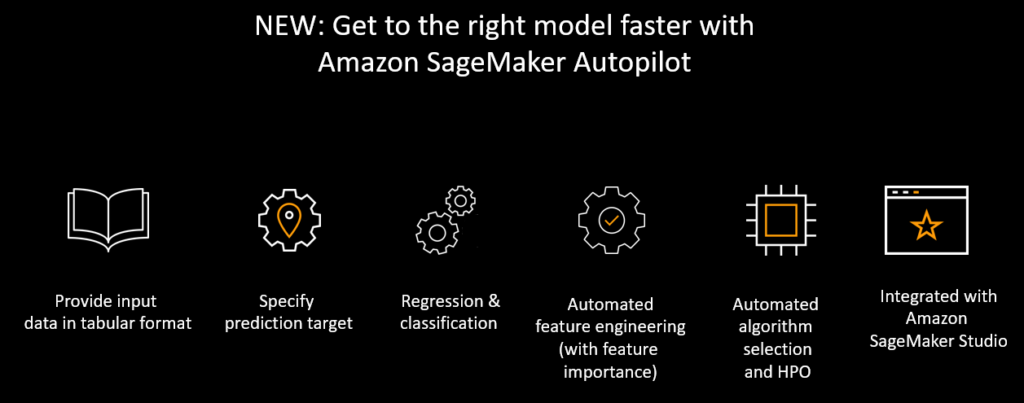
Typically with auto-ML one ends up with a black box: data is entered, outputs are produced, and the auto-ML system chooses the model that ends up going into production. But Autopilot is not a black box. It’s easy to see every model that was created and choose the right ones for each business case in regard to accuracy, latency, model size, and so on. SageMaker exposes the code so data scientists can go in and make changes to it.
These are just a few of the changes AWS has made to the machine learning stack over the past year. But we’re far from done. We’re innovating every single day. There’s still much more we can do to help organizations get more value from their data and drive machine learning across every aspect of their business.
We cover so much ground at re:Invent it’s hard to talk about everything, so I like to hit on a handful of bigger themes. For example, microservices is one of the most exciting emerging trends today. It started as an attempt to break down the monolithic model of computing, where each layer in the stack is assigned a team of people responsible for different processes.
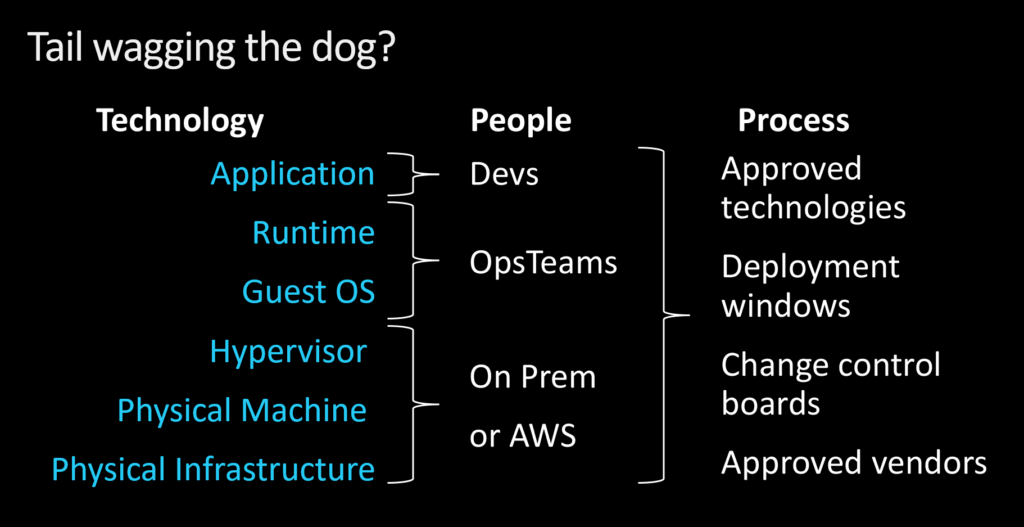
It’s supposed to be people, process, and then technology, in that order, but it’s become the opposite. Microservices simplify things by getting rid of the stack and empowering developers to build run-time applications. All they need to worry about is the app and where it’s running.
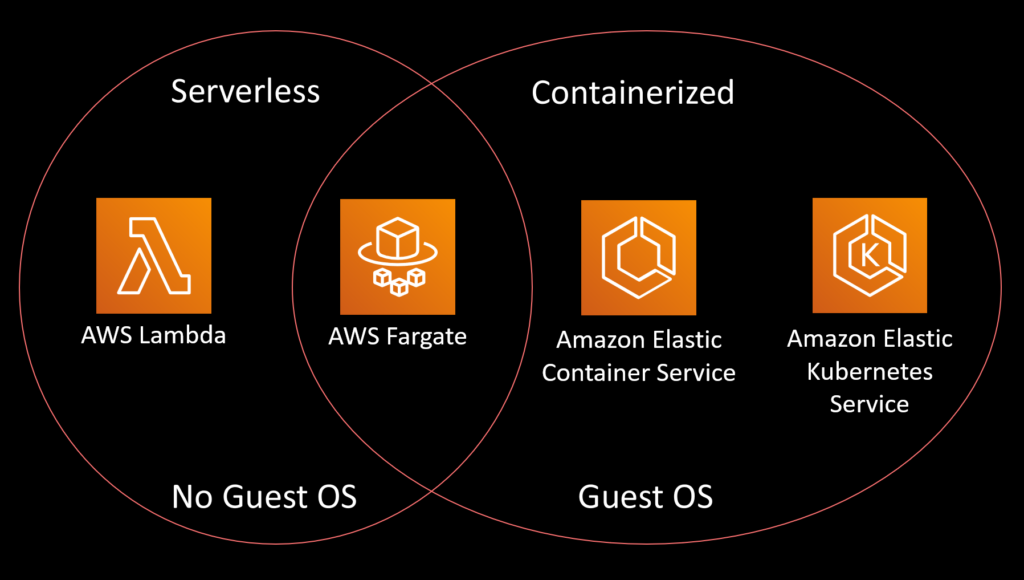
At AWS we split microservices options into four units. With Lambda you upload code and pay a fee for every hundred milliseconds it executes. Fargate is a serverless option that has no underlying guest operating system but runs containers instead of raw code. Customers who need more control over the guest OS can use Kubernetes or AWS Elastic Container Service.
The problem is that the number of microservices a company is managing can quickly spiral out of control. Here’s an image of all the microservices Amazon was running in 2008. We call it the Deathstar.

We had to create two firm rules to avoid this. The first was that every microservice team was responsible for all aspects of the development life cycle — testing, QA, devops, etc. The second is Amazon’s famous two-pizza team rule: If the number of people responsible for managing a microservice exceeds the number you can feed with two pizzas, that microservice needs to be split into multiple services.
So at re:Invent we introduced some tools to make it easier to manage microservices. HTTP APIs for Amazon API Gateway lets customers build full-on restful interfaces that integrate directly with Fargate and Lambda to help manage workflows. Fargate now also supports Spot, which lets customers take advantage of excess capacity on EC2 at a significant discount.
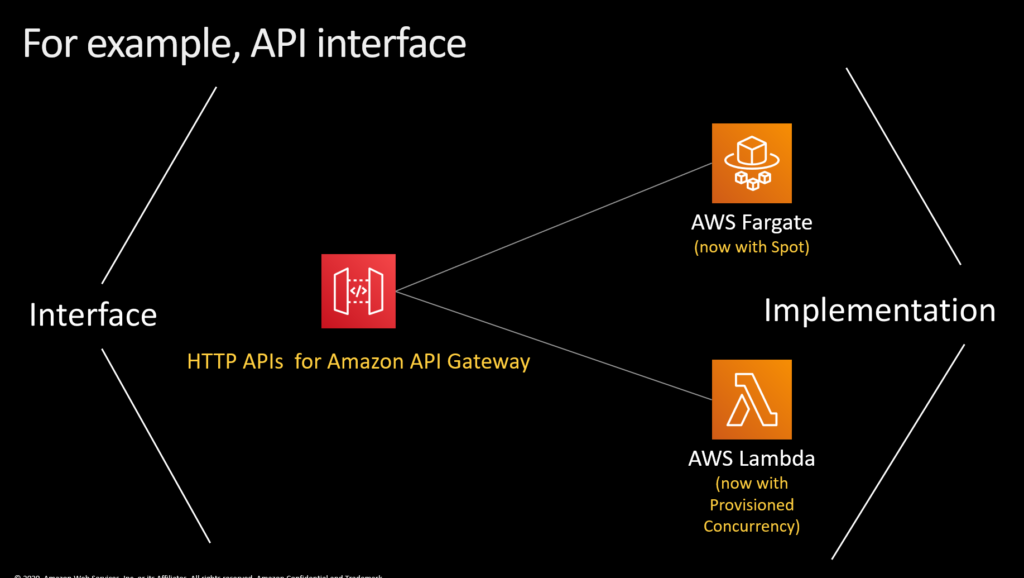
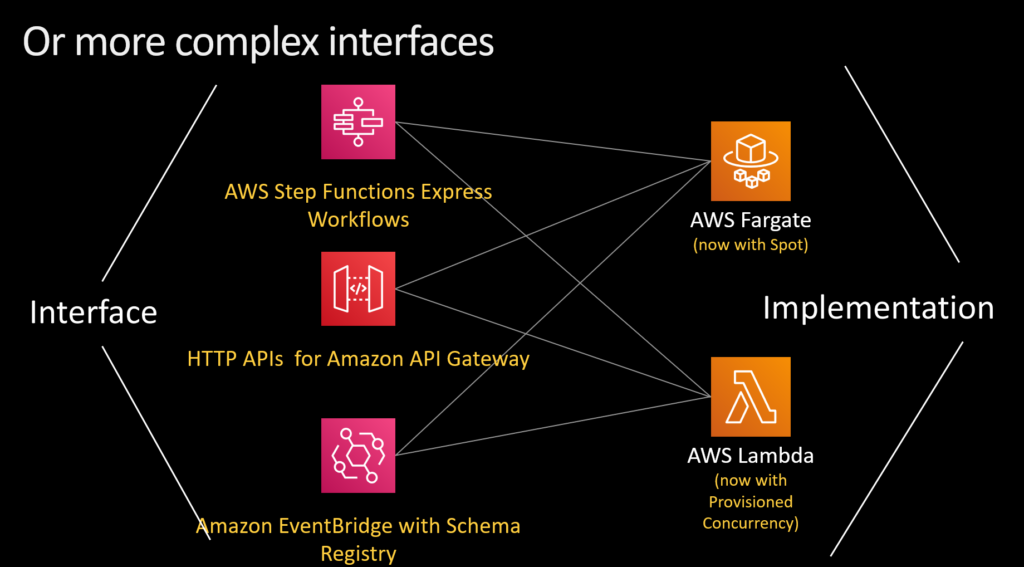
AWS Step Functions Express Workflows allows people with classic stateful workflow challenges to operate hundred of thousands of state changes a second. Amazon EventBridge integrates directly with Lambda and Fargate and makes it easier to build event-driven applications.
A second major theme from re:Invent is ‘hybrid cloud,’ a term that really isn’t aging very well. As you may already know, AWS resources are split into Regions, such as Oregon and Ohio, and Availability Zones indicated by the blue dots in the map below. If you live in Texas, as I do, you can get content cached locally but getting access to compute resources involves a round trip to and from Ohio or North Virginia.
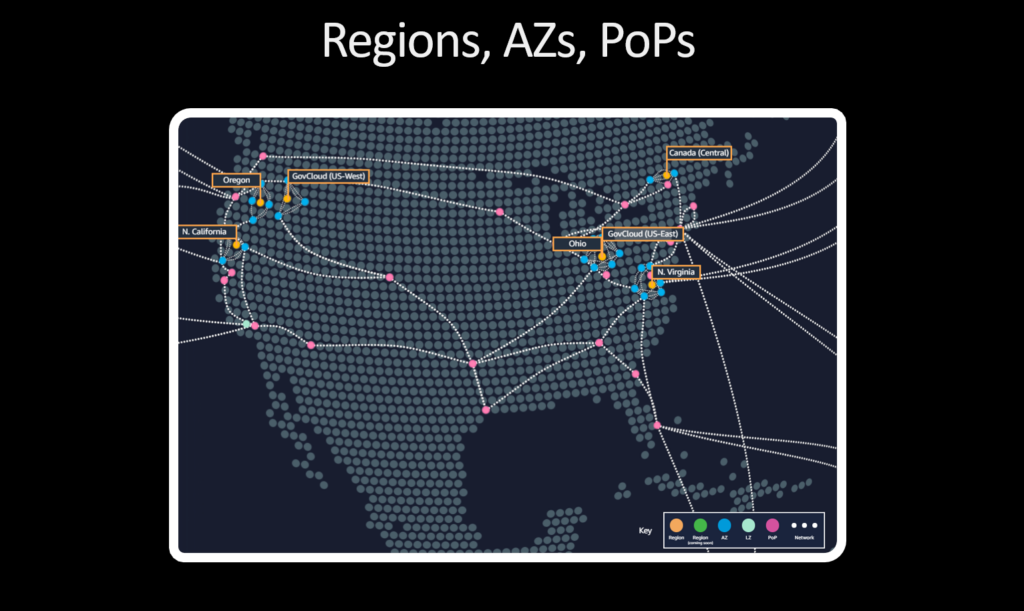
That means tens of milliseconds of latency. That’s not bad, but applications that demand sub-millisecond latency, such as augmented reality, are growing every day. So we announced two new types of Regions at re:Invent: Local Zones and Wavelength Zones.

Local Zones allow customers to deploy a subset of AWS closer to their physical location, reducing latency under ten milliseconds. Wavelength Zones are designed for 5G mobile users and bring some Amazon services right to the edge, resulting in latencies as low as a millisecond.
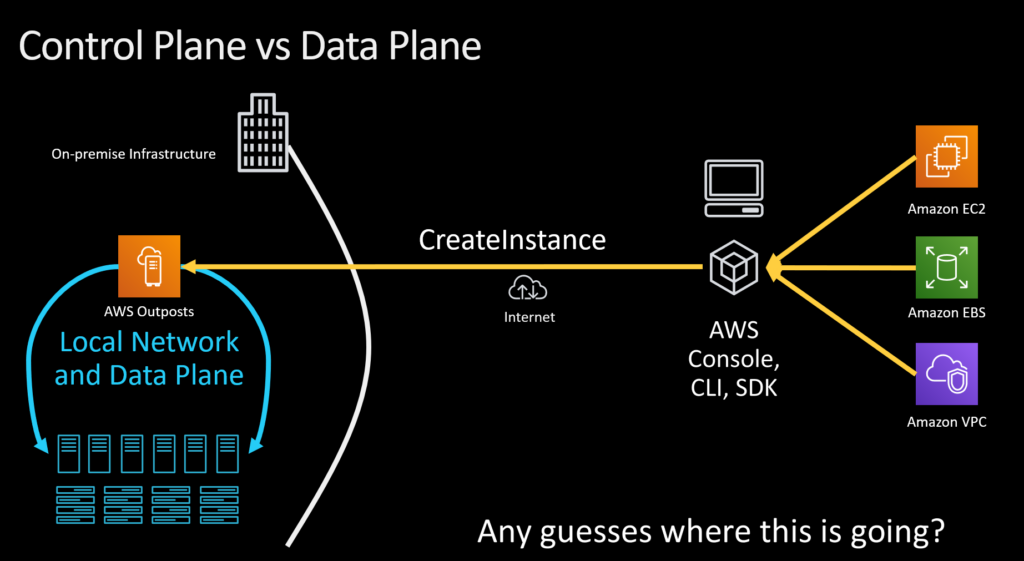
For customers that need more control over the location of their data, we’ve introduced AWS Outposts. These are actual pre-configured racks we deliver to customers, which they can keep on premise and use to create EC2 instances locally. All customer data stays in rack storage; only control plane actions cross into the cloud. This is a real accelerator for enterprises struggling with data sovereignty issues or latency challenges, and can help them prep for migrating fully into the cloud later.
Finally, I want to talk about what we call Hybrid Networking Hell. That happens when you have several client VPNs, on-prem sites, virtual private clouds, and route tables, combined with multiple AWS accounts across multiple regions. This is not only insane, it’s also critical to your business, because your disaster recovery solutions may rely on the connections outlined in this matrix.
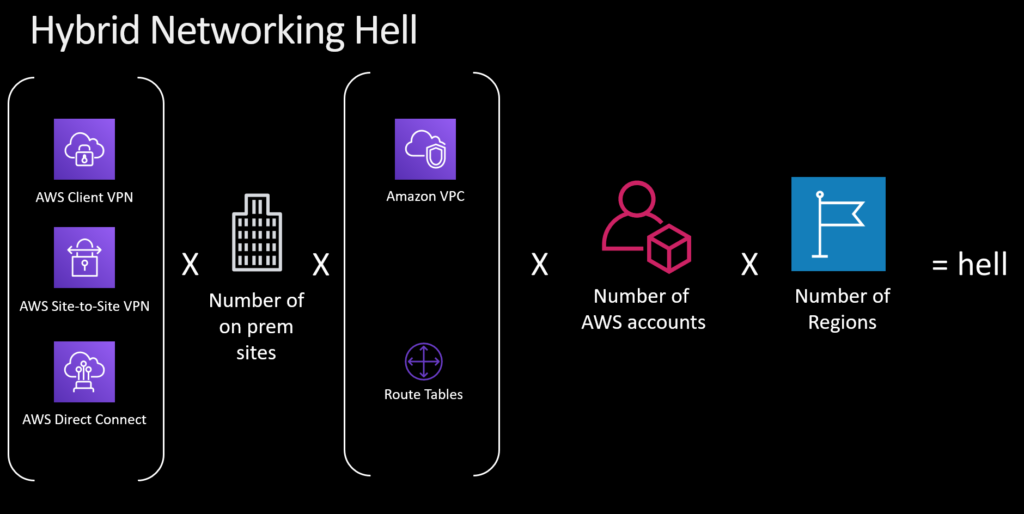
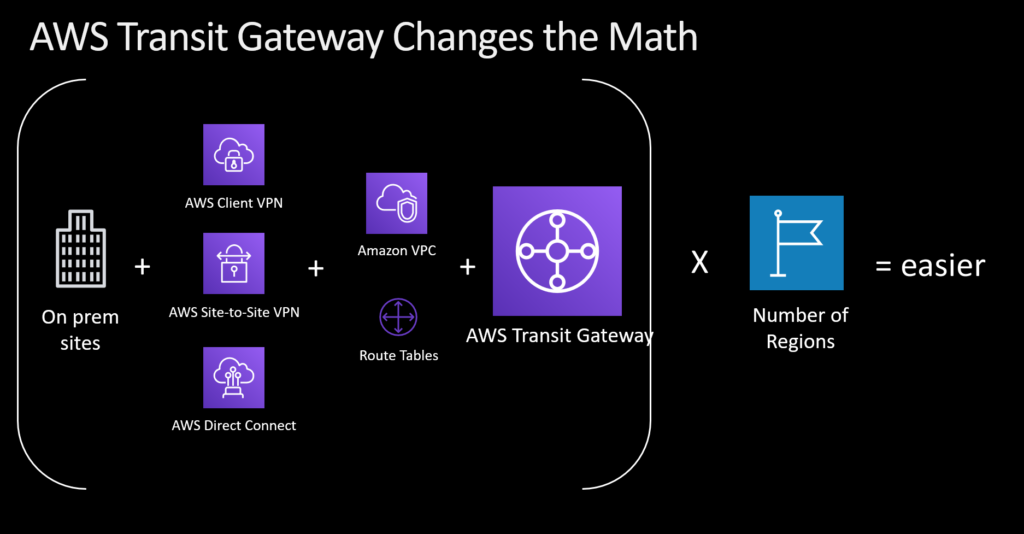
We introduced AWS Transit Gateway to drastically simplify this scenario. It takes that complex matrix and converts it to a more conventional hub-and-spoke model. I can’t emphasize enough how much this will simplify your network operations.
The last thing I’d like to add is that, for all the new things we introduce at re:Invent each year, the fundamentals of AWS haven’t changed. Amazon Simple Storage Service started out in 2006 as one service composed of 8 microservices. Now Amazon S3 has 262 microservices. It started out as a pocketknife and now it’s a power tool. But our mission is still the same: increase the number and value of solutions available to our customers, while decreasing their complexity.
We don’t charge license fees for our software. The fees for SageMaker are built into the cost of the infrastructure; you only pay for the computing power you consume while using it. But we do offer new users a free trial for the first two months. Each month includes 250 hours of t2.medium or t3.medium notebook usage for building machine learning models, 50 hours of m4.xlarge or m5.xlarge for training, and 125 hours of m4.xlarge or m5.xlarge to deploy models for real-time inferencing and batch transform. Your free tier starts from the moment you create your first SageMaker resource.
Bias is a common problem with auto-ML, where there’s a black box and you can’t see how the model has reached a particular outcome. There’s where biases in how the features are engineered and model is created can surface. We avoid that by exposing the code and highlighting where the biases in the model might be – these are the areas you should focus on, here are the levers you can manipulate, and so on.
Financial services and healthcare for sure. We’ve seen a lot of use cases that truly move the needle in terms of business value for both of those industries. We’re working with a lot of customers in insurance and fintech, like Capital One. There’s also a lot of great innovation happening in automotive.
We have lots of partnerships with people using those solutions. But once they’ve built their models, they’ve got to figure out how they’re going to deploy and monitor them. We think we have a fantastic full stack that offers every element of the process you might need. That being said, if you already have your own solutions in place, you can use parts of our stack to handle the rest.
We like to approach this in terms of personas. If you have data scientists who are writing code in Python or R, we feel like we have a fantastic IDE solution in SageMaker Studio. If you don’t have those data scientists but still need machine learning applications, you can still take advantage of the AI services at the top of our stack. We have vision, language, and other applied AI services you can access via APIs that can give you ML results without having data scientists and hitting all those speed bumps.
If you have heavy or dynamic storage requirements and you want use something like Better FS to achieve infinitely scale-able capacity for Docker containers, that’s a great reason for needing host access. But for things like Fargate there is no host, which limits the amount of storage you can apply to it. If you wanted to modify anything running at the Docker agent level you’d need a guest OS. But those are really edge cases. Probably 80 percent of the time you’d be just fine using Fargate instead of something like Docker Kubernetes Service or Elastic Container Service that would use a guest OS.