

Kubernetes is taking the app development world by storm. Already, 77% of companies with more than 1,000 developers that run Kubernetes are using it in production. Kubernetes is shaping the future of app development and management.
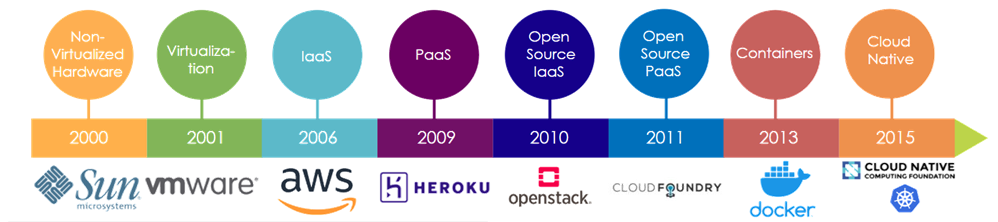
Cloud computing still required us to continue to purchase a rack of servers, and the building block of our applications were on the physical hardware. Throughout the move from a non-virtualized, hardware world to virtualization (while hosting on less hardware, still hosting on a physical server), to platform as a service, to open source, cloud docking containers, to now a world of cloud native –modern applications are increasingly built using containers.
It may be relatively easy to deploy a container, but operating containers at scale is anything but. It’s quickly become consensus that an orchestration tool/container management tool is a prerequisite for long-term success with containers. Using one enables greater automation, repeatability, and definability within your environment, while reducing a potentially crushing burden of manual work, especially as your container adoption grows.
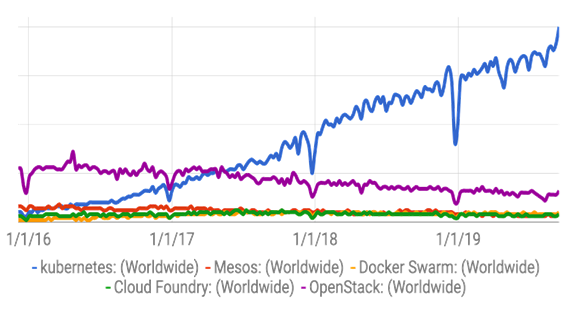
Kubernetes is something we continue to hear more and more about. Simply based on Google search trends (illustrated in the chart below), it’s clearly a topic of note and a topic people are interested in learning more about and exploring how to use it in more important ways in their organizations.

Brendan Burns (@brendandburns), Kubernetes Co-Founder, Distinguished Engineer, Microsoft Azure
Brendan Burns is a Distinguished Engineer in Microsoft Azure and co-founder of the Kubernetes open source project. In Azure he leads teams that focus on containers, open source and devOps, including the Azure Kubernetes Service, Azure Resource Manager, Service Fabric and Azure Linux teams. He also has contributed many significant pieces of code to the Kubernetes project, including most recently work on client libraries for working with the Kubernetes API. He has been involved in open source for more than two decades, over that time he has acted as maintainer for projects as diverse as the JMeter load testing tool, the DroidDrawWYSiWYGdesigner for Android and the port of the Quake II to Linux.
He has a PhD in Computer Science from the University of Massachusetts Amherst and a BA in Studio Art and Computer Science from Williams College.
History of Containerization
Although containers are often viewed as modern technology and are associated with modern application development and deployment patterns, they’ve actually been around for a while. Chroot was introduced in the late 1970’s, during the development of Version 7 Unix. This is the first development of what you might now consider a container; all it really did was change the root filesystem.
In the late 1990s, as the internet started to explode and people were thinking a lot about security, BSD introduced this concept of “jails” as a way to isolate different processes, namely web servers, on the same machine.
Solaris Zones followed suit, then Linux followed in the mid 2000s. In the case of Linux, it was largely driven by needs around resource isolation and attempted to maximize the resource usage on a particular machine.
Interestingly, the industry average fleet utilization is somewhere around 10-15%. You’re spending for 100% of the CPU, and you’re using 10-15%; that’s an opportunity for savings. The code in the Linux kernel was added to help improve utilization. People didn’t pay attention to the code sitting there, existing inside the kernel, except for the few people who were providing PaaS.
In 2013, Docker came along and captured the zeitgeist of what was happening in Cloud with things like immutable architectures and the needs around application deployment and agility, and came out with the collection of what is now known as Docker –which is actually a lot more than just the stuff in the kernel, that’s almost the least important part of why they were successful. Docker was very focused on the individual machine and then the node, and didn’t have a great understanding of how you group multiple nodes together.
2014 -Kubernetes was introduced as an application-oriented Cloud API. Cloud APIs prior to Kubernetes had been very infrastructure oriented, i.e. virtual machines, virtual disks, virtual networks, etc. The Kubernetes API differentiates itself by being oriented around the infrastructure as well, but infrastructure that is aligned with applications, as opposed to virtual analogs of physical components.
It came from a sense of how hard it was to build and deploy applications. We came to public cloud having built applications in a different way. Then, we started looking at the tools people were using, they just seemed extraordinarily painful. You’d see someone deploying a database or web server with something like Puppet or Chef, and their failure rates would be 10%, which is just crazy, but it was because the infrastructure wasn’t there to support deploying an application. So, we built Kubernetes because we thought we had a better insight into how to manage applications that wasn’t present in the cloud at the time, and it was really important to move the cloud forward. We had seen other ways to solve this problem, but they were either unavailable to people or available in only very limited ways in limited domains.
AIMED TO SERVE SMALLER WORKLOADS
Kubernetes, especially in the beginning, was and is still aimed at serving workloads, as opposed to HPC workloads. The HPC space has had solutions for a long time. Kubernetes was aimed more towards the microservice applications space, and has now evolved into the batch space. Our motivation was continuous delivery of applications and reliability of applications. In fact, I always told people that I thought that the scheduler was the least interesting part of Kubernetes, which is hard for people who spent a lot of time thinking about utilization and scheduling to understand. But the truth was, while HPC is extremely large and economically important, it’s a very narrow slice of the broader computing market and a very narrow problem for which you can design more purpose-built solutions, and have. Over time, we’re seeing the value of having a single data center API rather than multiple data center APIs means there’s a center of gravity towards Kubernetes, because if you use Kubernetes on everything then you can take advantage of peaks and troughs in your serving load to do batch work. But it comes at a price, because the Kubernetes default scheduler is not a HPC scheduler, so you have to sub in your own HPC scheduler in order to do the right things in that environment.
THE BASIS FOR EVERY NEXT GENERATION PLATFORM
5-6 years later, it never ceases to amaze me how many people are now using Kubernetes. We’re now seeing it as the basis for next generation platforms, which is the most important thing to note. From the beginning, I’ve described our API as Posixfor the cloud, it was never meant to be the final solution. It was intended to be the unifying system API that provided the same interface, no matter what it was running on (just as Posixdid in the late 80s), and then people were to build on top. Whether you’re looking at Cloud Foundry or Azure, where you can take an Azure function and run it as Kubernetes if you need to run it someplace else, Kubernetes is the basis for every next generation platform that anyone’s thinking about building.
No one’s saying let’s start with bare metal or virtual machines and build up from there. Everyone’s saying let’s start with containers and Kubernetes and build from there, and that’s the next 5 years -building out all of those platforms. Everything that Kubernetes does is operations oriented, not developer oriented. It really helps you run your application, but does very little to help you build your application. And that’s the future.
WHY DID KUBERNETES BECOME SO IMPORTANT?
One of the biggest reasons Kubernetes became such a part of the development zeitgeist is the relentless push towards API-driven deployments, cloud deployment patterns, and continuous software delivery. If you’re not feeling the pressure around this, then you’ve either already solved it or you’re not paying attention. This is one of the key insights. Agility and reliability are the key factors for people deploying applications. For example, you talk to some retailers who deploy their software once a month, if that, and they’re facing competition from people who deploy their software every hour. And reliability expectations also just continue to ramp up; downtime is now seen as a sign of untrustworthiness. If you go down, you’re seen as being less capable in your business, not just in your IT. That shadow effect continues to get worse. Those are two of the biggest reasons why there’s a strong continued interest in Kubernetes.
DESIRED STATE CONTROL – THE THERMOSTAT
Before Kubernetes, most software delivery to the cloud was feed-forward and not imperative –meaning you started a process, it ran for a while, it ended, and then your software was installed. At that point, the system let go and said you’re good, we installed you, and we’re never going to visit you again. With declarative configuration/desired state control, it says you actually need to continually revisit the state of the world and the desired state of the world and take online action to correct the state of the world to match the desired state. The best example of this that everyone has experienced is a thermostat. You set a desired state, a certain temperature, and that thermostat is continually checking the temperature and taking action, heating or cooling, to always hit the desired temperature. If you imagine back to the world of scripts and Puppet and Chef, it would be as if you said you’d like the temperature to be 73 degrees, and the process took all actions necessary to get you to 73 degrees, and then just stopped. And then no matter what happened, it took no further action until you asked it to do it again. I don’t think we anticipated how broad an impact this would have, but with the growth of operators and all sorts of other things, I think Kubernetes transformed how people thought about software being a feed-forward, run to completion system, to being an online self-healing, self-repairing system. It’s really important. It’s at the core of everything Kubernetes does, but it’s also at the core of the things that people are building on top of Kubernetes.
When people were looking at environments of virtualization, they were designed around two things: increasing utilization and fungibility –meaning if I have three teams and am not sure how they’re going to grow, it’s way worse if I have to buy physical machines because they’re hard to return and they amortize. Versus, if I have a virtual environment, I only have to buy one physical SKU and still provide Windows machines to the team that wants Windows, Linux to the team that wants Linux, and do things like that with more dynamic and scalable characteristics. If I give a machine to someone, I can’t really take it back in the middle of the night if I need to, but I can easily take away a virtual machine in the middle of the night. So both of those characteristics are covered by Kubernetes.
The reason we’re seeing this uptick in use on bare metals -no one was interested in virtual machines just because they’re interested in virtual machines. They’re interested in the characteristics of business processes that virtual machines allowed them to do on their hardware. If they can do the same thing with Kubernetes and not pay a virtualization penalty, there’s some value there. I think it remains to be seen. Obviously containers are not as secure as VMs, so in some cases, having a hypervisor there to act as a security boundary is important. The Kubernetes API was intended to provide a cloud-like or virtualized-like API on top of a group of machines that was shared by a bunch of different users, which is also what virtualization is providing.
Customers come to us often with these types of questions, and ask, for instance, should I have one cluster for my entire organization? Should I have one for each team? It’s sort of the same question, because if you’re going to have lots of clusters, you’re probably better off using virtualization because those clusters are going to have to scale up or down in response to the team or product’s growth. That’s going to be way easier to do in a virtualized environment. If you’re going to have a physical environment, you should probably only have one Kubernetes cluster in that physical environment. Sometimes that’s hard, because for example, chargeback in Kubernetes isn’t very well defined right now. So if you want to have 20 teams all on the same cluster and charge them based on what they use, you have to develop your own charging solution for now. That can be a problem for some people. Similarly, sometimes people might say ‘I can’t have anything other than a virtualization boundary between these two workloads,’ and if that’s the case, then you need to have virtualization. It really comes down to organizational ability to share resources more than anything else. The one large cluster is a shared resource, and you have to have a team that’s dedicated to maintaining that shared resource. If organizationally you can manage that, then that’s probably a great thing. But if having lots of little clusters is better for you, then virtualization can help you achieve lots of different clusters.
I absolutely see that. There are examples all over the place. For one example, when we created the Azure Kubernetes service, it originally created a virtual network as part of that. When we walk into some of these enterprises now, some of their developers are literally not allowed to create a virtual network. You have to file a ticket to the networking team to create a network in the cloud. So, despite this dynamic API that exists, their developers can’t take advantage of it because their infrastructure IT has said this is a capability that developers aren’t allowed. And we actually had to change our product so that it could be deployed into an existing virtual network, as opposed to having it be created so we could work around this particular issue. That’s an example where we needed to adapt to the enterprise. The fact that most app dev shops are outsourced, that’s a requirement we had to contend with. And for many people, when they do this outsourcing, they want to give them sort of a cookie cutter. Kubernetes has a lot of functionality that makes that sort of packaging and deployment easier. No matter what platform you’re operating on, or if you’re on Java 7 or Java 8, etc, the container itself can become an abstraction of deployment that helps unify a lot of the processes in these apps, even if the shops themselves are doing different things.
To name another example we’ve seen, Kubernetes expects to create load balancers with public IP addresses. For a lot of shops, that’s terrifying, and justifiably so because you never know what might be on the other side of that IP address. So we’ve actually gone and figured out how to get policy into Kubernetes so that CSO can say, yeah you have the ability to create a public IP address, but in order to do it, you have to attach a ticket that shows that your app has been under security review, or whatever it happens to be. The CSO’s office can’t say that you’re not allowed to use Kubernetes because it uses public IP addresses, they need to come back a little bit and say, okay what do we need in the system in order for us to feel comfortable with the fact that this developer’s creating a public IP address. And I think that’s how these organizations adapt, by getting back to basics –instead of saying “this is the rule,” really examining what was the rule established for, and is there another way to achieve that purpose?
The other thing I’ve seen is people saying “we’re Kubernetes now! So we must be DevOps and we must’ve digitally transformed.” It’s actually quite the opposite. Cultural transformations have to happen first, then technology comes second –technology can help facilitate cultural transformation, but it doesn’t lead cultural transformation, it can’t be the instigation.
When I look historically back at the origins of containers and Kubernetes, I think a lot about Netflix in 2012 and 2013. They really advanced this idea of immutable architecture. They were creating VM images and never changing them. You deploy a VM image, and if you need to make a change then you go through your whole pipeline and create a new VM image, then deploy thatVM image. It was a way of making things more homogenous and ensuring things behaved the same every time. But it was really painful for developers because VM images are very heavy and hard and slow to build. So the idea was good, but the effect on developers was bad. So that’s where Docker stepped in and offered immutable container images with a great developer process. So, immutable architecture, as advocated by Netflix in the early 2010s, is the first stepping stone towards containers, cloud native, and Kubernetes. At this point, if you weren’t doing that and you have people logging into the machines or containers to launch software, you’re definitely going against the majority at this point. The tools weren’t as well-developed in 2012 and containers weren’t as well understood, but at this point there’s no excuse for not building images with a continuous delivery pipeline and if you need to change, making that change through the pipeline and a new image, as opposed to repairing the image inside of the machine.
There are two or three ways in which Kubernetes can add value in these environments, and ways in which we’ve seen it help people. The first is that in many cases these applications are massively underutilized. For example it’s an HR system that runs at 1% of the utilization and most of the time it’s idle. Yet, if you buy a machine for it, you’re paying for a complete machine and it’s expensive. You can take those applications and pack them –in fact, you could take 100 machines and easily pack them into 10 machines by using Kubernetes, without having to do anything else (i.e. teaching the applications to be better citizens). That by itself can be a huge win for people.
The other thing you could do is provide a unified management and monitoring surface area. Those applications may have been built over a long history, but once you put them in Kubernetes, if they crash and restart, you can detect that through a consistent API. No matter how the app was built, the Kubernetes API was designed to tell you “hey, that app crashed and I restarted it” or “that thing’s been crashing for two hours, maybe you want to take a look.” Similarly, it can provide CPU usage, memory usage, or other information that tells you how that app is running.
The third use case, in that in many instances these legacy cases don’t exist in a vacuum. They’re important pieces of the business process, but they either can’t be modernized or it’s not worth it to modernize. I was talking to a GIS provider who did this -who has really important, but legacy Windows applications that do GIS from a desktop product that they released 10 years ago. They want to cloudify it, but they really don’t have the code, the ability, or the desire to take that desktop app and turn it into a cloud app. But they can sort of containerize it, and if they can containerize it and then build cloud native applications around that same environment, then that’s a huge win for them, just having their new and old stuff coexisting in the same place and following the same deployment patterns, that becomes so valuable too.
I definitely wouldn’t advocate for lifting and shifting in every environment. There’s definitely a place for pure lift and shift, but there are some wins from it as well.
Fundamentally, the biggest problem is that there are more applications that need to be built than there are skilled developers to build them. I think that we continue to try and find sort of the VisualBasicor Java equivalent, and I don’t think we’re there. I think we’re in a place, like in 1985, when the only tool that existed was C++, and it was too hard for most people to do a good job at. That’s a way of me saying that I see the problem, but I’m not sure I know the solution. People have tried, Heroku, for example, but they only hit 10-12% of the market. So there are these PaaS that can do a lot, but there are sort of these walled gardens that have real limitations. So, the question is, how do you design a programming environment so it has the right kindof limitations so that developers don’t end up getting trapped? I think we’re still experimenting with that. I created an experiment a while ago called MetaParticlethat was an attempt, and in all honestly it didn’t catch fire. It’s this weird intersection of, can you design a system that you think is the right system, and then also get it to capture the interest and usage of those enterprise developers? I’m beginning to believe that incremental adoption is critical. So, it can’t be sort of, re-write the world! It has to be more like, this will work with your existing stuff and make it a little bit better, and you’ll slowly move from the way you’re currently developing apps to the new way of developing apps. I also think storage management is obviously the biggest problem that most people have -how do you give concurrent access to storage in a sane way, while making sure not to corrupt things? That’s the problem. If we didn’t have any state, life would be easier.
I was talking to the tools people at Microsoft; they have this great history of developer tools. I sort of said, I just don’t think the tools we have today understand what the developer is trying to do in the cloud. They don’t understand the broader context of 20 different microservices talking to each other. And I think we have to figure out a way that you can express that first, because the tools need that insight in order to do intelligent things. I joke that we need something like Clippyfrom Microsoft Word… “it looks like what you’re trying to do isn’t going to work!”
There are too many tools and too much stuff to learn. To get stuff out to Kubernetes, you have at least 3 tools and at least 3 file formats. That’s probably at least 2 too many. We have to figure out ways where people don’t have to learn as much. We’re still struggling with it; honestly, it’s something I think about a lot.
I think that one of the things you have to realize is that it’s a full suite of what you have to do. People might say “I need containers and Kubernetes to get cloud native.” Well, that is a piece. And they’ll say “I need continuous delivery, so I’m going to use Jenkins or Azure DevOps to get cloud native.” And that’s good, but actually you need a lot of tests. So there are steps people don’t take. They’ll say “I set up my pipeline and now I can deploy every hour, but I don’t have any tests to show that it works.” Well, that’s not going to work out very well. In many respects, having the tests first is a better place to start, even though it’s a much less exciting place to start because you’re not necessarily becoming any more cloud native, because you’re not yet using containers or continuous delivery or Kubernetes, but the truth is, by doing this you become much more automatable. Without tests, all of that tech isn’t going to help you, it’s just going to make it easier for you to shoot yourself in the foot. In general, as an industry, we do a really bad job incentivizing our teams to do the stuff that is actually needed to become cloud native: to build tests, to build good monitoring, to build infrastructure around integration testing and deployment, and things like that –because we want features. And everyone who’s not a tech person, and even some tech people, all they can see is when is that user going to get this feature? That’s the part of the cultural transformation that has to happen along the way to cloud native. It’s not just, oh we can deploy our software really quickly, it’s also the services mentality that you have to have that comes along with that.
There are a number of these. Spinnaker is very opinionated, and if its opinionationworks for you, then that’s great -it does reduce the complexity. It helps a lot with deployment, but it doesn’t help with the development of the application itself. There are tools, certainly a lot of people are trying to figure out how we do this. It’s certainly something worth taking a look at, and it comes from Netflix, actually, so it goes back to that immutable infrastructure.
It’s worth really considering the fact that once you learn the technology, it’s really a cultural transformation. Microsoft went through this transformation; we were a box software company, and I think we can talk with empathy from our own continuing experience. Firstly, the only way to achieve cloud native is to get complete buy-in from all stakeholders. It’s not something you can impose from on high. Likewise, it’s something very hard to grassroots bottom-up. You’ll never get a complete transformation without collaboration between executive leadership and the people on the ground. Also, incremental. One of the challenges I often see is companies deciding to take their most elite team or CPO’s office and send them to learn Kubernetes, and then apply it across everything. That always ends in failure because there are too many people who aren’t included in that process. So instead, if you figure out how to take a small step forward, but with everyone included, and then take another step forward –maybe it’s just everyone improving their unit test coverage –that’s going to step you down the right road across your entire company, rather than having the “smart kids” going to figure it out and come back to deliver to the masses. I’m a big believer in broad, incremental steps, rather than big band transformations.
Training
CNCF’s Free Introduction to Kubernetes
Kubernetes for Developers course
Kubernetes Fundamentals course
Certification
Certified Kubernetes Administrator (CKA) Program
Certified Kubernetes Application Developer (CKAD) Program
Further Reading
What is Kubernetes?
Kubernetes Learning Path
Azure Kubernetes Service