


For our latest CXO Insight Call: “Generative AI with Google – The Enterprise Primer,” we were joined by Josh Gwyther, Global Generative AI Lead for Google, who shared an expert’s POV on where LLMs are at today (and where they’ll be tomorrow), what’s possible in the enterprise today with generative AI on Google Cloud, and what some of the best practices and pitfalls are for the enterprise. New opportunities emerge every day in operational efficiencies, cost savings, and value creation. This includes how companies can build, tune, and deploy foundation models with Vertex AI, personalize marketing content with Gen AI Studio, and improve conversational experiences with Gen App Builder.
Wide ranging concerns persist around the security and maturity of today’s AI offerings, and enterprises, unlike consumers, have many important needs around controlling their data, avoiding fraud and security breaches, controlling costs, integrating existing data and applications, and ensuring outcomes are accurate and explainable. Read on to learn about how the Google Cloud AI Portfolio will be tackling enterprise readiness, AI data governance, and open & scalable AI infrastructure.
What’s Happening in the Market? (Enterprise)
What’s Happening in the Market? (Startups)
Generative AI is not new to Google, in fact, it dates back over 20 years prior. AI was always intended to be the mechanism by which Google would scale search, and the components were all there, back as early as 2000. The mindset was that eventually the team would utilize generative AI to facilitate search at scale.
Very early on, Google put the pieces of the puzzle together and realized that the core components of AI for search are:
Compute and massive data centers are required to train the models. Then, as much data as possible is fed into them (in Google’s case, all the data of the internet). And finally, understanding is required in order for the models to recognize patterns in that deep set of data.
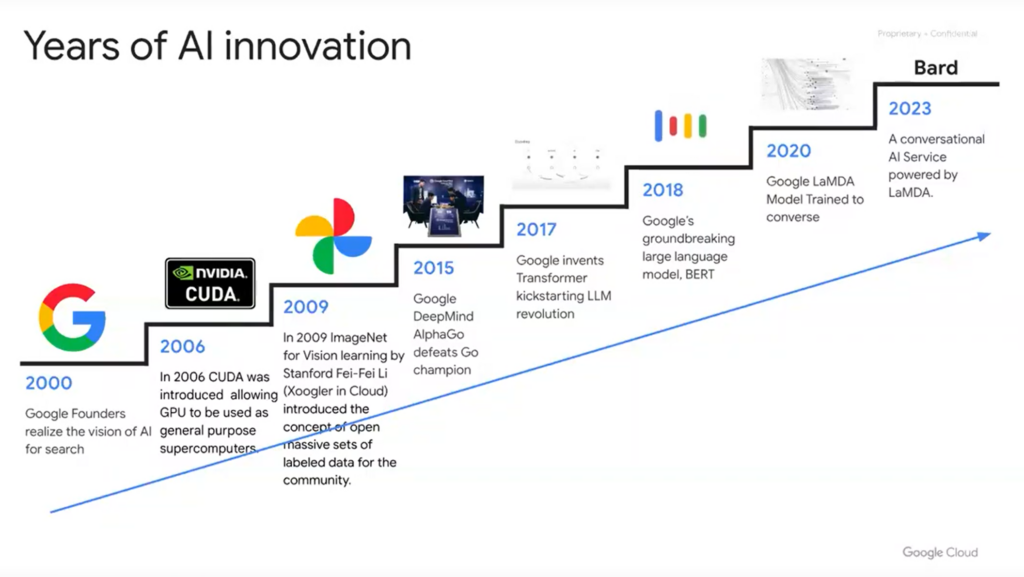
If you move forward along the timeline above, these are the pivotal events in the formation of where we are today with generative AI. A big leap forward took place in 2006 when nVidia released CUDA. This is a pivotal moment in generative AI history because it really democratized the supercomputer. This allowed everybody – universities, companies like Google, etc. to create supercomputers at scale, cost-effectively.
The other pivotal moment relative to Google’s march down this path was in 2009 when ImageNet was created for vision learning. Back in 2009 and 2010 there was a lot of work attempting to figure out vision classification with machine learning. This seems trivial now, but the epiphany moment that Fei-Fei Li had at Stanford was that maybe we just need a larger training set, and that with a well-labeled, massive dataset of images, vision models would be able to classify images at the same level as a human. This was a hard task at the time.
So, Google figured out a more scalable way for training sets to be labeled. Every image on the web has an alt tag, which was supposed to be there for accessibility. So if you had a blind user surfing the web, the tools they would use would actually communicate to them via that alt tag what they were looking at. In essence, the work was already done before it began. That was a huge step forward in proving out that a large amount of labeled data enables vision classification.
The next challenge that Google had was language. How do you translate sentiment across multiple languages? You need a machine learning model that can translate between any language on the globe, and derive context correctly. Labeling images is straightforward, but context around written language is very tough. Phrasing and word placement is tricky. In 2017, the Brain team came up with a paper called “Attention Is All You Need” which was really the invention of the Transformer Model. So when you hear the T in GPT, that’s what it’s based on. Instead of trying to label text to understand translation and natural language processing, the team just took all the text that was on the internet, and transformed it into numeric variables, and then looked for patterns. And the attention part of that is not just looking for patterns for the next word, but also paying attention to the words up front that it’s being compared to.

Think of old school Mad Libs: you had to fill in the verbs, or the nouns, and make funny sentences. What the team did was take all the data’s conversational text information, transform that into numeric values, then run it through the model over and over again, taking portions of the phrases out, until the model was positioning the right phrase in those sentences.
This was essentially the birth of the generative AI movement, because they found out that even without context, giving enough examples of how humans communicate symbolically, we can understand human context, fulfilling the third requirement necessary in order to enable generative AI.
One of the reasons Google has been slower to market despite this breakthrough back in 2017, is because they knew about the problems with hallucination and alignment right off the bat, and as a large company, they were very cautious, as they did not want to erode any trust in Google search.
One of the major areas that differentiates Google in this market is that they have to invest in generative AI. It’s the core of how they scale their products. They aren’t building models like Bard and PaLM to create a new revenue stream, these are core to their capabilities for their direct to consumer products. So investment in Google from an AI perspective is not new, and nor will it slow down, what is new is that now Google is allowing companies to gain access to these models via Google Cloud. This is accomplished via their platform, Vertex AI.
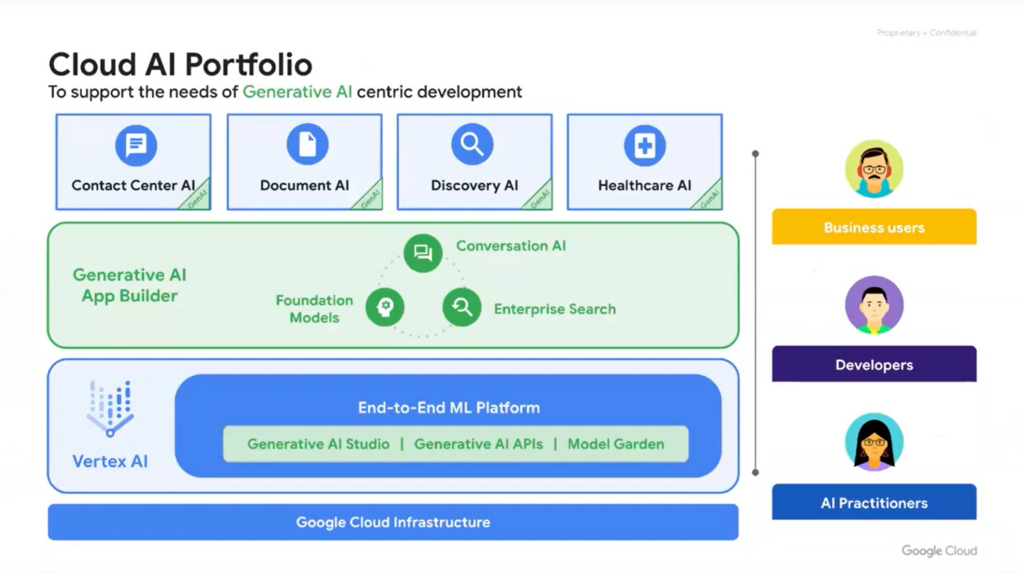
This has been around for a while, it’s the machine learning portion of the Google Cloud platform. But, new components have been added around generative AI, e.g. Generative AI App Builder, Generative AI Studio, Model Garden, etc. This is intended to be an easy-to-consume marketplace for deploying and leveraging models on Google Cloud.
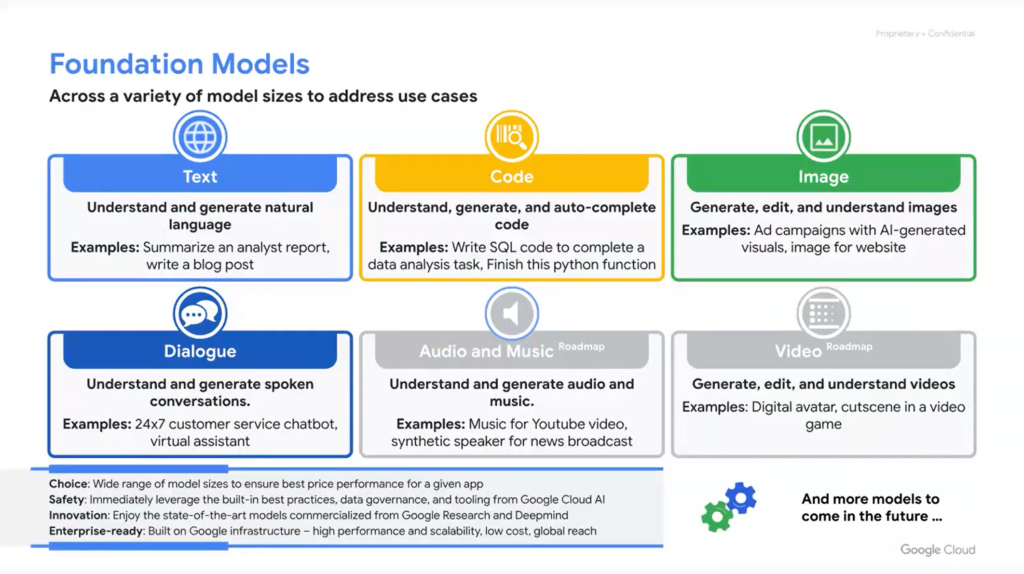
Right now, Google has foundational models available in text, code completion and generation, image generation, dialogue or chat, audio and music (soon), and video (soon). These are being invested in from both a B2B and B2C standpoint.
When considering how to best customize your enterprise models, it’s important to first understand the difference between fine-tuning vs. embedding.
Fine-tuning is the persona of your model – if you want your model to respond in a certain way, almost like giving it an accent, that’s where fine-tuning comes in. This is how you have a model respond the way you want. In the case of PaLM, for example, there is a version for the medical profession, Med-PaLM, where you really want the model to have the vernacular of a medical professional. That’s not trivial, however, it took weeks and millions of dollars to do. Cybersecurity is another area where fine-tuning is often needed. But typically, unless there’s a very specific need to have a model be very precise in terms of how it responds and functions, usually fine-tuning doesn’t have an awesome ROI.
Embedding is augmenting a model’s dataset with an additional form of data (often data that is frequently changing, which doesn’t necessarily need to be a part of the foundational model itself).
For example: If you wanted PaLM to glean insights on internal documents within your organization, you wouldn’t fine-tune the model on those documents, that would just make it “talk” like the document, while still using the data from your general corpus. With embedding, you can take that document, run it through the embeddings API, and ask questions based on that specific data. First, the document is queried, then that’s circumvented to the foundational model to say “hey, summarize this!” The foundational model wouldn’t be able to get that data on its own because it doesn’t have access, and it would just wind up hallucinating a nonsense answer.
There have been a number of early concerns around data security with regards to foundational models. For example, is data being sent to foundational models being collected and used to better train them? For Google, this is segmented completely in Google Cloud. Customer data is not being used to train foundational models. Those weights are frozen, and if you want to fine-tune that model, they create an adaptive layer of neurons (a caching layer) that sit within your projects, like a DMZ between you and the foundational model. So, you can augment the skill set of that foundational model with your own data and your own training that will only live within your project. There obviously is a shared foundational model behind it all, and your question does get sent to that foundational model for interpretation, but it’s not stored and it’s not used for training.
Even then, that can sometimes be a sticking point for companies (people get into the weeds on how the memory works, and how long that memory state lasts etc.). One of the big questions that comes up is “Can I just run an entire version of PaLM inside my own project (because I don’t want anything being shared)?” That is likely going to be the direction in which things evolve. The reality is that if you wanted to run PaLM within your own project today, that’s possible, it’s just a very compute-intensive and cost-prohibitive thing to do right now. The new hotness is going to wind up being how small you can get these models while still performing the base level functions you want. Google is super focused on that, all the way down to being able to run localized models on Android. So eventually, depending on the level of functionality of the model, you’ll have the option to run the whole thing within your project.
Any company that is using customer data to train their own foundational models is a red flag, because fundamentally, what goes in can come out. And it’s usually just in bits and pieces, but if you’re actually training a shared model, there’s a probability that whatever it’s being learned on, a fraction of that can resurface as an answer. So there are very real concerns around IP in that circumstance. Google is being very explicit that that’s not the direction they want to move in.
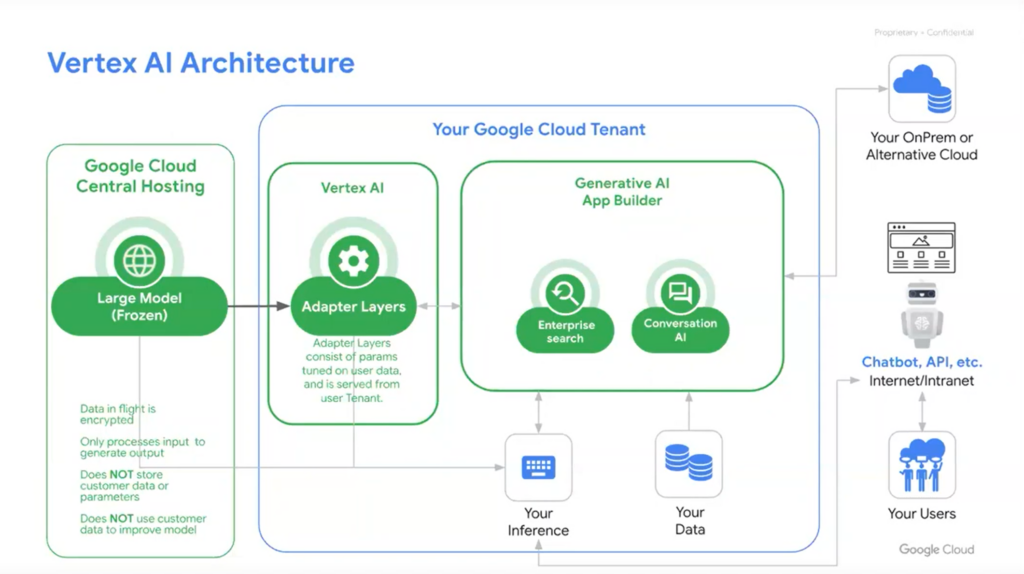
Google has always been a huge investor in AI, regardless of the current market, because of the business need in their direct to consumer products. These new foundational models are just internal services being exposed to enterprises in a consumable format on the cloud.
So fundamentally, Google is embracing third party and open source models. For them, it’s not about competing, but about bringing them to the platform and allowing you to access them on Google Cloud. Google doesn’t care if you’re consuming their model or someone else’s. There will be some big announcements on this very shortly.
There will be a lot of experimentation over the next year or two with generative AI. Foundational models are going to be widely available to anyone who wants to use them, so the focus right now should be on private data and the security aspects of that. If you’re experimenting with different cloud providers, you want to make sure that the cloud provider will support 1st party, 3rd party, and open source models, because that’s just going to be the future.
You’ll have an application stack that’s making calls to multiple models – larger foundational models for high-level tasks, smaller more efficient models for some base language processing, etc. So what you should be looking for in the early days is ensuring that you have a choice of models, and that you can land your application stack next to those models.
There will be a lot of pressure for open-source solutions, because depending on who your end customers are, they will ask you to be on xyz as a constraint of them using you. Open-source can be a great answer to that. If you want to be multi-cloud, you’re going to have to be multi-stack. If you have a customer that’s on GCP and a customer that’s on Azure, and you want to use generative AI, then your stack is going to look different, because the way these models respond to prompting is very different. You’ll need some portion of the stack that’s interpreting and responding with PaLM, and then on the Azure side, a completely different portion of the stack will be working with OpenAI. Customers today are already trying to figure this out – load balancing between foundational models is a hard problem to solve. Open-source allows you consistency across cloud providers.
Models charge for words in and words out (processing). That’s hard to provide a rough estimate for, because it all depends on what you’re asking the model for and how you’re asking it. When you hear about prompt engineering, teams are basically surrounding a question with context in the prompt, and some of those prompts can get very elaborate – up to thousands of characters long. So depending on how much you need prompting for, or how much you use prompting vs. embedding or fine-tuning, it can sway your costs on a generative AI application pretty heavily.
When most of us as laymen are directly inputting questions to a model, our prompt looks like the question that we asked. But in application development, when you really want to get these models to do complex functions, you’re surrounding it with pages of prompting information to get it to act. That’s not editable by your customer – that’s in the application stack itself. Every one of those characters has a cost associated with it, and depending on how often your application is asking for data from the foundational model, that can exponentially increase the cost. That’s the starting point: look at how you’re going to interact with that model, how often, and how big is the prompt (+ how big is the response back to the model)? Design is very important.
