


For our latest CXO Insight Call: “Generative AI – From Big Vision to Practical Execution,” we were joined by Sreekar Krishna, US National Leader for Artificial Intelligence at KPMG and Erik Bovee, Head of Business Development at MindsDB, who spoke to what a pragmatic generative AI path to success will look like in today’s large organizations.
Even before ChatGPT, one-third of CIOs said their organization had already deployed artificial intelligence (AI) technologies, and 15% more believed they would deploy AI within the next year, according to the 2023 Gartner CIO and Technology Executive Survey. But deciding how best to proceed means factoring AI into business value, risk, talent, and investment priorities. As a next step, CIOs and other organizational leaders must create an AI strategy roadmap that synthesizes the enterprise’s vision for the future – outlining potential benefits, while mitigating risk, capturing KPIs, and implementing best practices for value creation.
Sreekar spoke in depth on how businesses should be thinking responsibly about AI best practices and making them foundational to AI strategy, as opposed to just an afterthought.
Over the last couple of decades, businesses have been implementing a variety of different strategies around AI and data science – but many of these efforts are now dated, or even in direct conflict with the new wave of generative AI solutions coming to market. So the question now arises: How can companies transition their prior AI efforts over to a generative AI approach, with value creation as the top priority?
KPMG sends out a global survey every 3 months to C-level executives in the Fortune 500, and their most recent survey focused on generative AI specifically.

Over three quarters of the executives who participated expect that generative AI will have a large impact on their organization over the next 3-5 years, as measured by increasing workflow productivity. And 60% plan to implement their first generative AI solution within the next two years. This is regardless of where these companies are on their AI journey today. Advancing initiatives in this space is seen as increasing the moat around the business.
IT and tech are the definitive early adopters as this new wave is coming in the form of SaaS products that have fantastic API integration. However, finance, HR, procurement, sales, and many other areas that have traditionally relied on unstructured data are starting to make a lot of impact.
That’s not to say there won’t be challenges: Over 90% of respondents believe that generative AI introduces moderate to high-risk concerns – especially in areas such as IP, legal and security. Furthermore, over two-thirds of companies have not set up a centralized person or team to organize their response. This is still the case even in very large organizations that haven’t been traditional power users of AI, particularly in the back or middle offices. This is difficult for the business which will ultimately run into major challenges like: “How do we make this work?” “Who do we go to?” “Do we need permission for X?” etc.” Engineers and data scientists are already dedicated to front office functions and building the product, so there needs to be some sort of ownership around the back and middle office.
Furthermore, talent is somewhat of a challenge both in terms of availability and how teams are organized. Data engineers and data scientists are hard to recruit. But on the upside, IT has been completely embracing generative AI. It’s much more exciting than the previous generation of AI, which was positioned as just one more thing to help the business with. Every business unit would come to them with a new AI model that worked a different way.
Now, what we’re seeing is data engineers, software engineers and integration engineers actually bringing generative AI use cases to light. This is happening within the IT function itself, so there’s a lot of adoption bubbling up from the grassroots of tech players within large companies. Data scientists are now becoming SMEs to IT specialists, with IT using data scientists as subject matter experts, in order to better understand how xyz model is working. This is in contrast to the prior generation, where IT and data scientists were peers in taking a model and making it production-ready. Data scientists were expected to answer the data engineers’ questions and IT integration questions, and they struggled quite a lot with that. Now data scientists can be good at what they’re good at: interpreting models and outcomes.
However, there are emergent funding problems here: heads of data science are starting to question if they are being proportionately funded relative to the IT function’s spend around generative AI. Do they have enough funding and support to really address all of these new use cases? It could be that data science’s funding model will be integrated within the business function where they are supporting all the growth that’s happening there. For companies that are sticking to the center of excellence model, they are proportionately beginning to fund data scientists more as they are proportionately more involved in these new generative AI initiatives. Data scientists aren’t necessarily needed to start an AI engagement, but they are needed to help support ongoing AI engagements.
Finally, there are definitely risks in place around these new technologies like cybersecurity, data privacy, etc. And when thinking about the regulatory landscape, it’s important that these new concerns are addressed in a methodical manner.
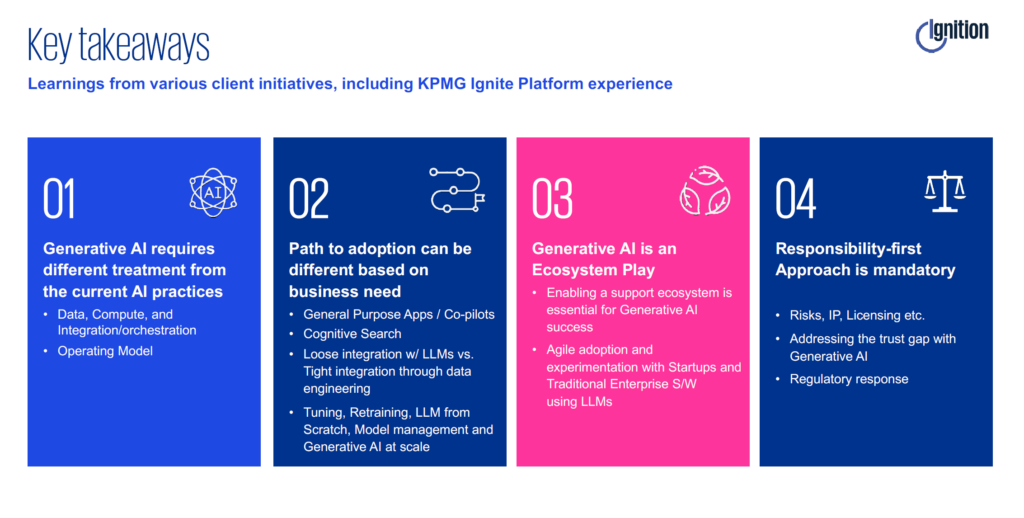
There are four key takeaways that the KPMG team has run up against working on various client initiatives. First, generative AI requires a different treatment when contrasted with the AI practices of the past. You no longer need a data scientist in the room just to talk about AI.
This leads to point two, which is that the path to adoption for different business units within each organization is different. For some teams, just enabling and white labeling GPT is enough for them to get started and get value out of generative AI. For others, an AI app may be required to produce a software that can integrate with the system and have data flowing through, which is a different adoption curve.
The third piece is that generative AI has become an ecosystem play. Previously, companies had a whole conversation around buy vs build, e.g. “Should I go with a certain environment depending on my use case?” Now, we’re in a place where certain kinds of AI must be bought, and certain kinds must be built. It has become a buy and build game and that’s where your ecosystem is going to matter a lot. Your data players who are providing your data today, either third party or internal data, can now all use LLMs to offer you not just data, but insights. And at that point, they become part of your ecosystem, the same way you could be part of someone else’s ecosystem, giving them insights yourself. Raw data is still important, which is why data engineering has been so huge the last few years, but now we’re starting to see insights moving between business groups and integration points.
Finally, a responsibility-first approach is going to be so important. We all know the risks with generative AI. Unlike with the previous waves where it was easy to do a small POC, and teams could think about the responsibility side later – that aspect is now becoming more front and center. It’s important to address the risk, the IP issues, the licensing issues. This could be even broader like an employee entering PII information accidentally, or bad actors poisoning the prompts, or a consultant using hallucination output, etc. This must all be addressed in stage one of the MVP before it’s taken further. Some thoughts here include focusing heavily on employee literacy and education (e.g. mandatory LinkedIn Learning or other programs), avoiding the use of client data in the early innings, or having a controls layer within the API that tracks things like social security numbers, names of people, phone numbers, etc. Prompts can be blocked if they are getting into PII. Furthermore, other products can be brought into the pipeline to help block prompts that create problematic exposure.
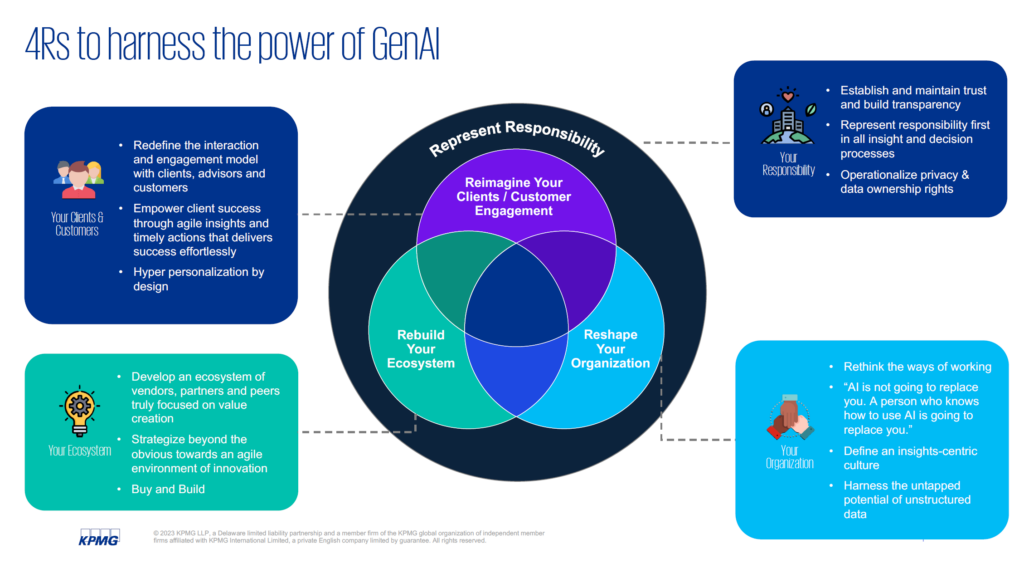
So, in response to all these quandaries, KPMG has come up with what they’re calling the 4R model to harness the power of generative AI.
Using the horizons model, it’s clear that we’re already seeing companies beginning to traverse the curve. Horizon 1 is well underway within the back office and middle office functions of many businesses today. Generative AI is going to production, particularly in financial service institutions like insurance. Traditionally, they have been slow to adopt these kinds of technologies, but now, they are moving quite fast. Many F500s and otherwise are putting generative AI models into production as we speak.
Horizon 2 will start to happen in late 2024, or early 2025, and we’ll begin seeing generative AI models interacting with clients and customers. On the B2B side, some of this is already starting to take shape within sales and client interaction models. Then, in 2025 and beyond, new and disruptive business models will start to emerge. Private equity is already trying to figure out how to spin off portions of their portfolio into automated generative AI business models that will go to market in the 2025 timeframe.
So, with all this in mind, what does the roadmap really look like?
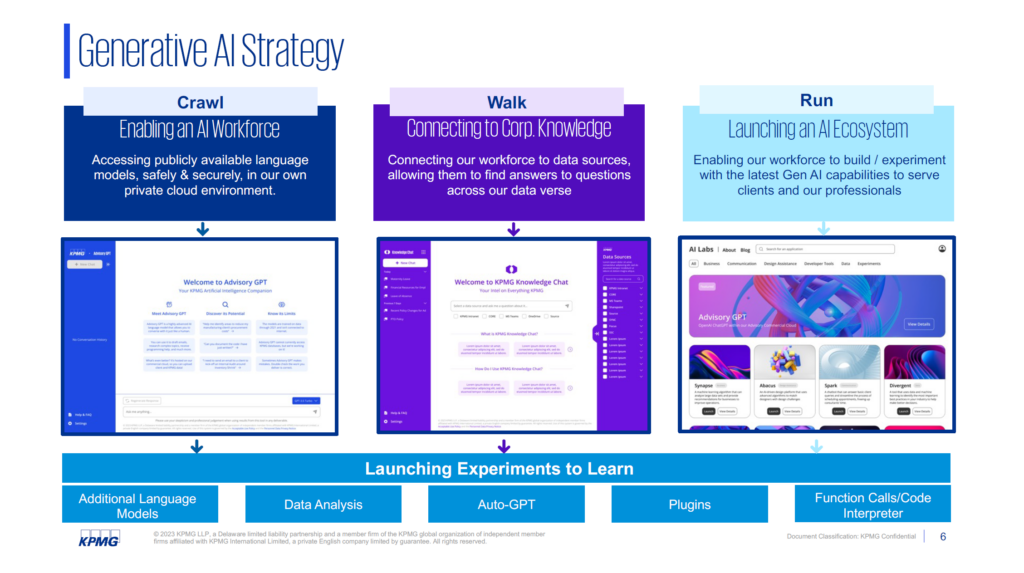
There is an emergent “Crawl, Walk, Run” strategy for getting started with generative AI without wasting too much effort on strategy.
When getting started, it’s important to prioritize business use cases. This is a very important piece of the puzzle. When considering use cases, consider effort vs. use case area. The diagram below gives a good sense of where businesses should start: clustered around the blue line. Crawl for back office and middle office, while progressing towards a front office run function as a strategic play.
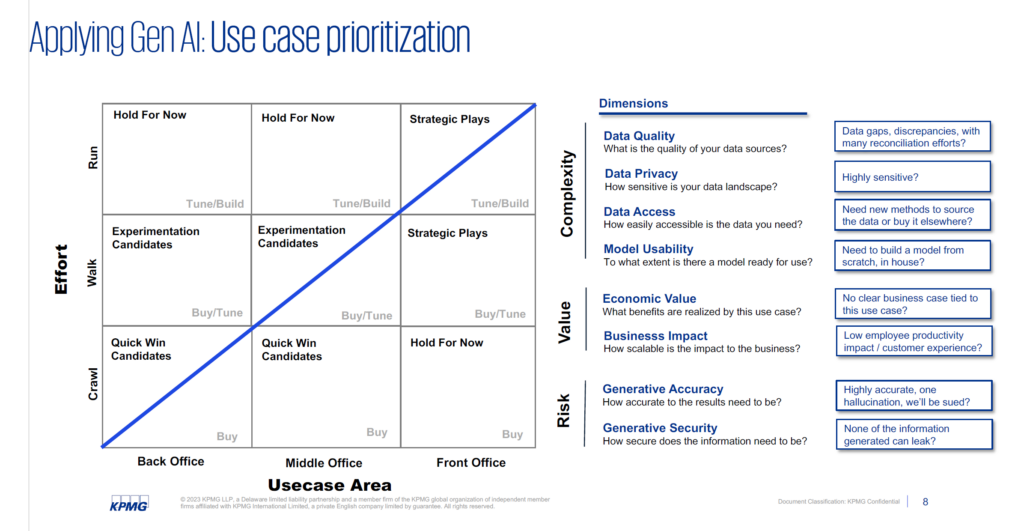
Some things are quick wins, some things are experiments, and some things should be held off on given how rapidly this environment is changing, and how many new players are entering the market. But at the same time, staying quiet and assuming that something is going to emerge in the future is not a good strategy either.
When it comes to “Crawl / Back Office” – just enabling white label GPT for the back-office (call centers, internal audit, etc.) may already add a lot of value to the mundane tasks they’re completing. But coming to the middle of the function: “Walk / Back Office” – it could be smarter to just buy a foundational model and fine-tune it in order to solve a particular set of tasks. A good example here would be a cognitive search engine custom-built for the call center, an assistive agent they can ask quick questions to about product, customers, call histories, etc.
Finally, when thinking about “Run / Front Office,” the strategic play, the idea is to envision how to completely disrupt operations. For example, futurizing call centers where interactions are entirely with generative AI models, rather than with humans, as a first step in the process.
“The Crawl” requires two important elements to be addressed: foundational enablement within the organization around how things are going to happen, and the change management that goes with it.
KPMG As a Case Study
KPMG has created an API control layer within which they are launching a lot of foundational AI models: LaMDA, Claude, ChatGPT, etc. These models have all been opened up for any employee to access. ~80,000 US employees now have access to AdvisoryGPT within the advisory function and the adoption has been phenomenal. Within two weeks, they had an active user group of 10-11K employees on a weekly basis, using this new functionality for many different questions and prompts – all of which are then being harvested by the data team. Now, KPMG can look at what kinds of questions people are asking. What kinds of use cases are they looking for? Where do they sit in the organization? How can they be better enabled?
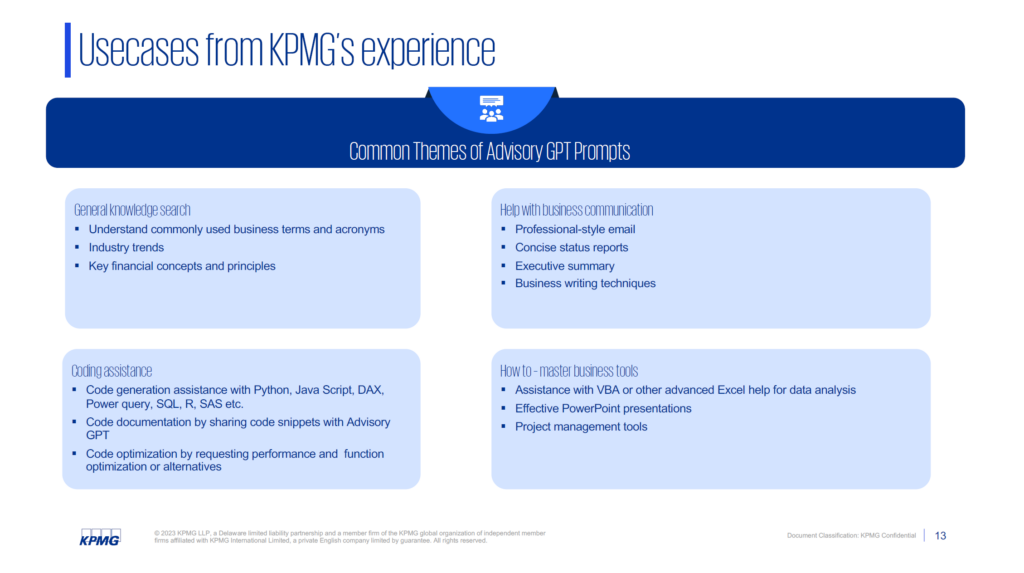
These are all log-level details coming through PowerBI, with a dashboard that functional leaders can view. These kinds of details help develop a roadmap around what further capabilities should be built out. Ergo, the crawl program can help to create a map around what the walk and run programs ought to look like over the next 2-3 years. And this can be cheap, <$10,000 a month.
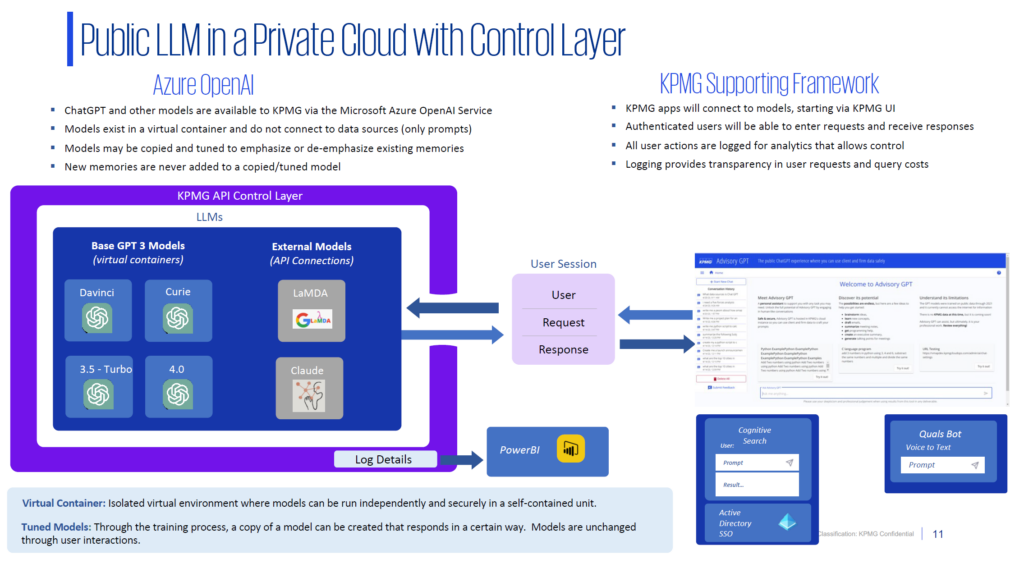
The architecture above was built with ChaptGPT as the first initial cut, using Azure OpenAI services. KPMG created a private endpoint with Microsoft, and that private endpoint is controlled by IT layering and preventing any kind of external access to it. So, it’s not connected to the internet (aside from just their team and connections into Microsoft).
In essence, this is a private, securitized, endpoint within Azure where this OpenAI/ChatGPT endpoint is running and does not connect to the internet. It’s a static model that is left within the four walls of Microsoft’s network. Anything that is sent as a prompt lives inside of KPMG’s Azure instance, and the rules are set in such a way that Microsoft cannot access the data. These are the same security controls that they are using for their Gov Cloud. Any data produced in the OpenAI environment is subsequently pulled into their Azure environment, so that the data doesn’t live within OpenAI, but instead within their Azure controlled environment. That’s where all the PowerBI and log details are coming into the network.
Getting started can really be as simple as using a consumer-grade ChatGPT virtualized into an enterprise environment. Fine-tuning is not necessary to start crawling. Without enabling this secure access for employees, those same employees are going to explore on their own.
“The Walk” requires two important elements to be addressed: data mobilization and workforce acceleration. This is where data starts to become the key to success. Data must be enabled to flow to the right places at the right times. This is going to be a huge piece of the puzzle. Different data components will need to be integrated into a seamless channel in order to feed whatever different models are being built. The LLM portion needs to be plug and play on top of a fixed and static data piece.


But at a high level, organizations are going to be looking at:
The buy and build part of the ecosystem comes into play once organizations want to take things to the next level.
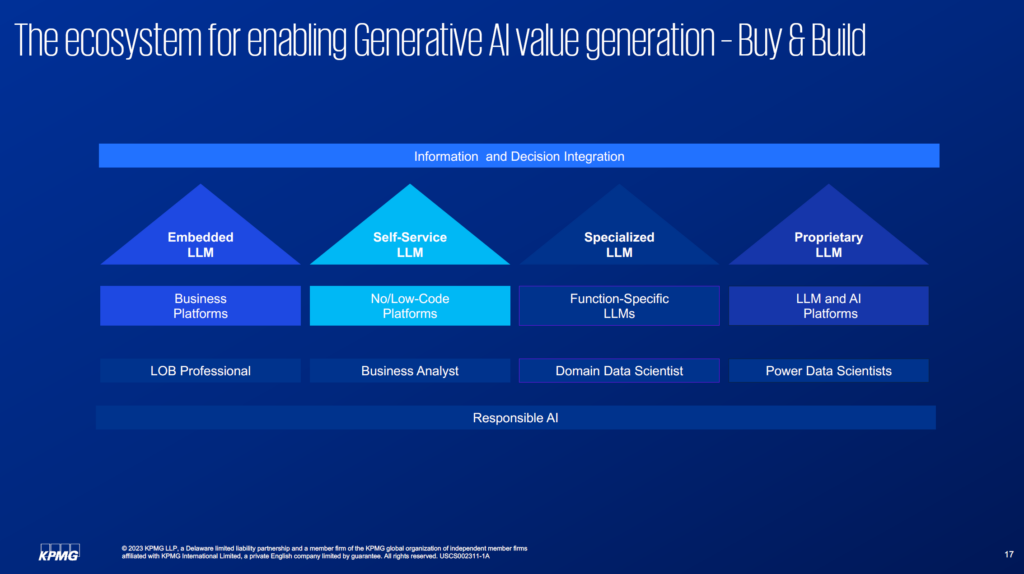
There are, generally speaking, four major types of use cases in the mix today.
When considering this landscape: the “Buy” end of the spectrum is on the left, and the “Build” end of the spectrum is on the right. In between are use cases that may require a little bit of fine tuning. Taking only the buy or only the build options is a mistake. Companies must be engaged in the information and decision integration process – how can all of these new tools be integrated in a secure manner?
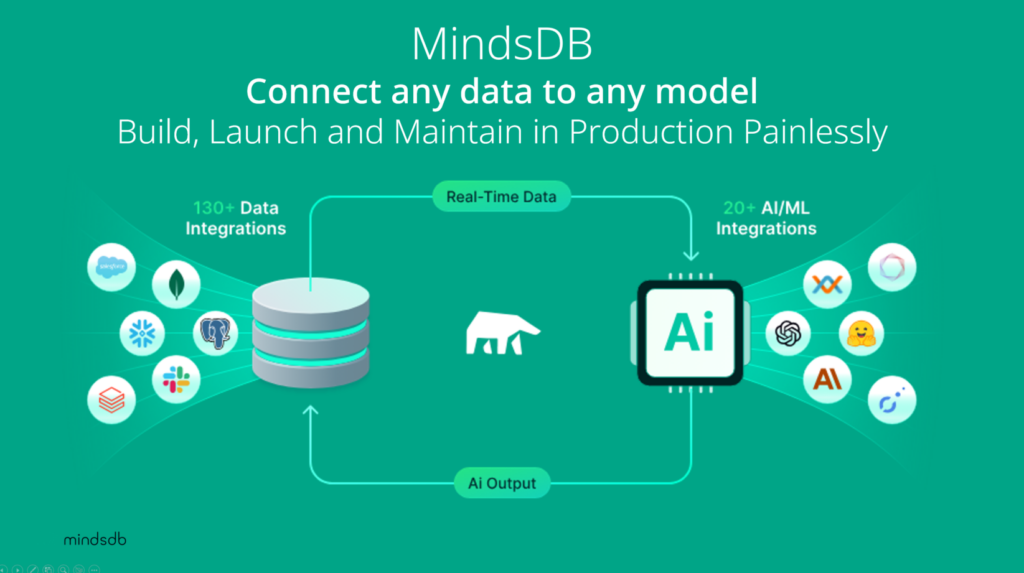
Furthermore, many companies are emerging to help simplify all the commotion. One of our portfolio companies, MindsDB, has created sophisticated middleware to help connect any data source to any AI model, including a business’ own models that are in production. All this while providing an abstraction layer that allows developers to still use their preferred developer framework to build sophisticated AI applications, move them into production, and maintain/update them more easily. The goal here is to allow any developer to implement quick TTV use cases, while still being able to support the most sophisticated use cases. The best way to take advantage of the opportunity AI presents, is to place that opportunity into the hands of every developer.
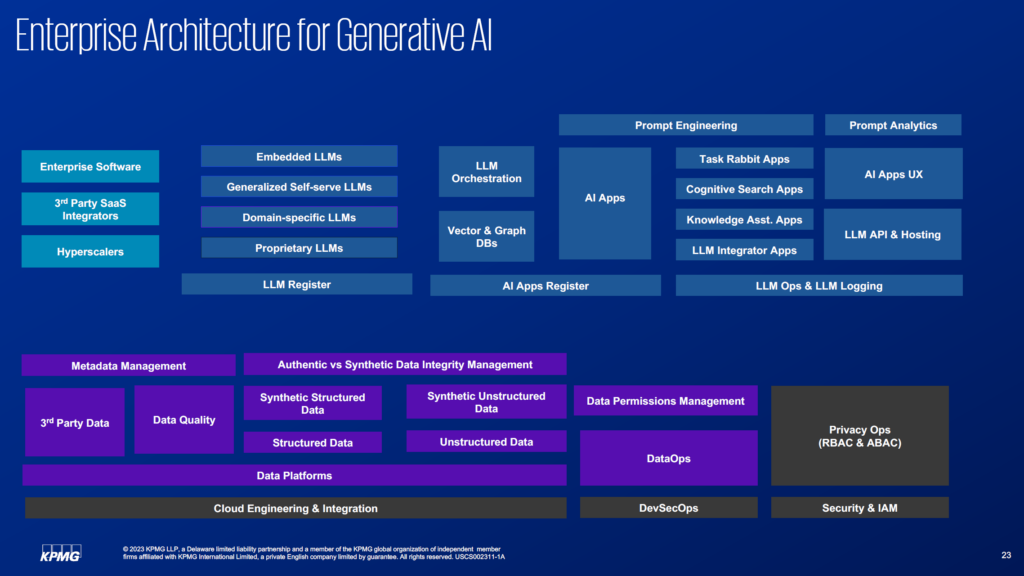
The focus is going to be all about ensuring that architecture can enable enterprise-wide, responsible use of LLMs. This will involve:
Certain elements are going to be absolutely necessary to reach the “Run” phase in terms of enterprise architecture. Privacy Ops (RBAC, ABAC), security & IAM programs, as well as good devSecOps, cloud engineering and integration will be key factors.
Structured and unstructured data will also be huge. Unstructured data will be growing really fast and the governance of synthetic vs. authentic data will be key. Registering what type of LLMs are being brought into the company (are they coming from a startup, cloud provider, or are they internally built?) will need to be tracked, as will AI apps. Harvesting prompts and prompt analytics will be an important piece that also must be enabled within the architecture. LLM orchestration will be huge, vector and graph databases will be huge. How to enable all these things will be a huge piece of the program that will need to be built out.
It’s an exciting time for the modern organization, the activities that promote scale in AI create a virtuous cycle. Interdisciplinary teams will bring together diverse skills and perspectives, and employees will start to think bigger—moving from discrete solutions to completely reimagining business and operating models. Innovation will accelerate as teams across large organizations get a taste for the test-and-learn approaches that successfully propelled these early AI pilots.
Companies that are able to implement AI throughout their organizations will retain a vast advantage in a world where humans and machines working together outperform either humans or machines working apart.
1. Would you mind talking more about PE firms thinking through GAI spin-offs, are they trying to launch companies with a scaled down GAI only operations?
PE firms are looking into using Gen AI to optimize operations in their new acquisitions. They are also looking inside their own portfolio companies to see if there are candidate companies with proprietary industry-specific knowledge which can be packaged into LLMs, and be spun off as companies of their own.
2. On C’s description of RAG (retrieval augmented generation), what level of success do people see with this and do you expect to continue to build it internally, or buy a solution for this?
RAG is showing a lot of promise, but it’s yet another advancement in the Gen AI algorithmic growth. We’ll definitely see more advancements come through in other techniques. Hence the suggestion that when it comes to the “Run” model, it’s important to build an enterprise architecture that allows efficient orchestration of LLMs and algorithmic techniques around LLMs.
3. Aren’t some of the quickest wins and low hanging fruits for generative AI in the “Front Office” (e.g. Customer Interactions)? So, could one “Run”” without the “Crawl” and “Walk”? Or, am I reading the matrix wrong?
Given some of the concerns with Hallucinations and the need to monitor the outputs from Gen AI, our recommendation is to have some thin veil of controls before exposing everything to front office. Granted, if all you’re doing is opening an experimental experience for your customers, or clients, you can provide them with enough fine print, and just open things up. But if the goal is to aid in real decision-making, especially critical decisions like financial, legal, health etc., it’s important to consider front office applications as being more risky than back and middle office use cases.
4. Where would you put using AI to write code in, re: Crawl/Walk/Run?
It depends on how integrated the code generator is within the enterprise. If it’s just allowing coders to use ChatGPT to write better code, it’s definitely a “Crawl.” However, integrated technologies within the dev environment would be more like a “Walk.” Finally, fine tuning foundational models with your enterprise code base and creating very specific code that was custom delivered for your applications is more like a “Run.”
5. What about the talent challenge, is it reasonable to assume organizations can hire this talent or should we be looking to leverage experts from consulting and/or solution providers?
This goes back to building your ecosystem. If you are able to build an ecosystem that has vendors, consultants, data providers, product companies, etc. then the conversation is not just around talent, it’s also around process and technology. You may be able to solve some aspects of the talent challenge with process or tech (startups). Also, we’re noticing that as Gen AI technologies mature, companies are wanting to invest more in their Data Analysts, because those are the SME who understand the business better and are the core source for “growing the business.”
6. How much effort was needed to create the underlying data or cleanse/normalize the data to make these LLMs effective?
This depends on where one starts from. Some of the proprietary LLMs are very good out of the box. In fact, there is evidence now that one could deteriorate the outputs from some of these very large LLMs if you try to tune them too much into a narrow domain. On the other hand, smaller LLMs can do much better in specific tasks when trained with even very small volumes of data.
7. Can you cover what type of risks you’re seeing in KPMG (internally and with clients)? How are you addressing these?
IP is one of the biggest ones. There are many questions around what is considered unique knowledge to the firm, especially if Gen AI was used to develop a writeup, or code, or image, etc. Hallucinations is another big one. We want to make sure models don’t lie about facts. Cybersecurity around models to ensure no one is injecting bad data into the training process (Insider Threat) or choking the LLMs (e.g. DDoS). Legal risks still are very high, especially controlling the legality of use. The best mitigation has been a prudent and measured approach to the use of Gen AI in specific use cases. Creating the Tiger Team that is able to spearhead conversations ahead of the use cases will be important.
8. Are you getting a lot of requests / needs from clients around VectorDB? If so, how do you deal with embedding vector in the raw data?
Yes, but VectorDBs have become a natural extension to the use of LLMs. Now the focus is shifting to the use of other novel approaches, including ‘context aware chunking,’ ‘graph embedded contextual vectors,’ etc.
9. Are you seeing any best of breed products for Fine tuning, RAG, ETL, etc. outside of the cloud vendors and OpenAI?


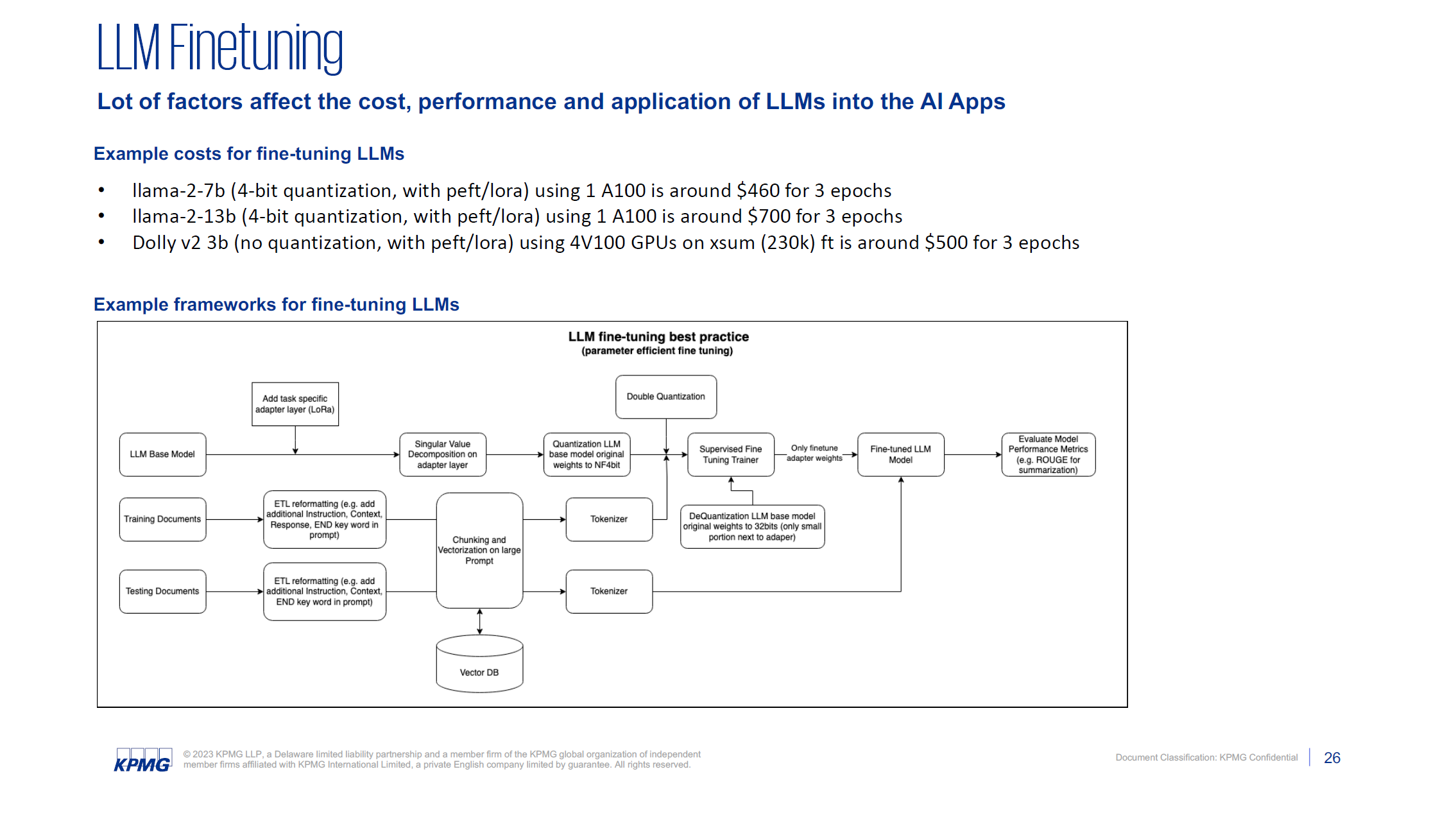
10. What is the average time from first discussions and ideas to PoC/MVP in your experience?
Two weeks is the fastest turn around we’ve done with our clients, but the client’s tech stack and data must be ready for the use case in order to move at that speed.
11. Since everyone is doing crawl/walk/run, how can you build competitive differentiation?
In our experience with the Fortune 100 to 500 companies, very few have executed even the “crawl” program well. Further, this differs by industry also. The tech industry is definitely ahead of the curve, but even within the top tech companies, the use of AI is restricted to their product side. When it comes to their middle and back office, even the most well known AI companies struggle with enterprise AI.
12. What happens to AI when all content owners (like NYT) mandate that their content be removed from all LLMs, AI engines, etc.?
Very good question. Maybe there are startups who are looking to license all data to train their models, and such an LLM would truly be able to provide content that is completely licensed.
13. How are you (or how do you plan to) measure quality and effectiveness of implementations for these use cases?
This depends truly on the use case at hand. For example, finance use cases must have numerical quantitative measures of success, while generated documents, or reports, need to be measured with some of the more NLG metrics for measurement. Human feedback is an expensive, but time tested way to measure the outputs also.
14. Why did you pick OpenAI / Microsoft vs Google or Open Source (e.g. Llama2)?
We were already an Azure stack, the decision was easy. Further, looking into the security model, privacy model, etc. Azure OpenAI offered the best first step. Having said that, we have already enabled Llama 2, Claude 2, Dolly, Falcon etc.
15. How do you see the landscape evolving between Proprietary LLMs vs Open-source and is Multi-LLM going to be important?
Open-source and proprietary-source conversation will continue to dominate the same way it has with other technologies we have experienced in the past, e.g. Operating system, database technologies, cloud technologies, etc. LLMs are facing a similar trajectory. It will be important to see how enterprises are able to stand up capabilities to orchestrate LLMs within their four walls. If they are able to manage the operational overhead, open-source will have strong adoption.
16. Are there any other foundational tools/applications (e.g. Langchain, Github Copilot etc.) that you see as critical to broad GenAI adoption at KPMG or amongst your clients?
Yes, we consider these technologies to be important pillars within the ecosystem. The ecosystem varies depending on the industry and the maturity of the client, but we see some of these technologies as being foundational.
17. How did KPMG internally build a business case for setting up the Advisory LLM ?
We are committed to the Generative AI future all the way up to the board level. In fact, we just established an internal executive role that reports to the CEO/COO that focuses on evolving KPMG’s consulting services backed by Gen AI. Further, the leader chosen to run the new function previously ran the entire advisory consulting organization.
18. Which LLM models are better for which purpose in your experience?
See question #9
19. How are you measuring the impact/ROI of these solutions? Are teams tracking time savings, cost savings, etc., to get a sense of the value created?
We definitely have to create measures of success depending on the use case at hand, and the business case at hand.
