


For our latest CXO Insight Call: “Generative AI and the Future of Artificial Intelligence,” we were joined by amazing speakers Adam Goldberg, Head of Azure OpenAI Enablement and Anju Gupta, VP Data Science & Analytics at Northwestern Mutual. They shared an expert and practitioner’s POV on how to build a business on top of OpenAI’s large language models (LLMs), and where the challenges are today.
For some time now, machines have been able to master the art of analyzing data – but unfortunately, they have struggled to create new content. OpenAI and the many models being built on top of it, mark the beginning of a new category widely known as “Generative AI” – meaning that an AI is generating something novel, rather than simply analyzing or acting on existing data. And this evolution won’t just apply to traditional creative work – every industry will feel the impact. Adam will be discussing how businesses will be able to leverage OpenAI in a very practical sense – and how some of the first big use cases will look.
A wide range of commercial applications are already beginning to take advantage of large language models ranging from gaming, to learning and development, to productivity and automation. Developers are generating various design layouts, SQL queries, complex CSS, and even cloning websites. Finance and legal can automatically translate documents or generate documentation. Teachers can populate quizzes and worksheets, and artists can create unique animations. The list of use cases is near endless: anything that involves a particular language structure is capable of being disrupted.
When you think about “generative AI” it’s a kind of model – the ability to generate the next word based on all possible combinations (and this could be in the trillions). The beauty of the GPT models is that they can run that many combinations at the same time, pre-trained on a lot of text from the internet, 175 billion parameters to be precise. This has never happened before. It’s a deep neural network, a class of models that Google released back around 2017. Many people have been playing with that kind of network architecture, but until OpenAI, it was never used to the extent that OpenAI has been able to accomplish. The amount of complexity here is astounding.
Over a decade ago, Marc Andreesen said that “software is eating the world” – and he was pretty spot on: since that time, nearly every company has become a technology company in some form or fashion. Now, we’re entering another vast transition: the next decade is going to be about “Large Language Models eating software,” as these LLMs are beginning to fundamentally redefine the essence of software.
This AI transformation is going to be really different, both in terms of the speed at which it’s moving, but also the fact that it’s truly presenting itself as a platform you can build on – and that becomes really meaningful when you look at what this means for your organization. At the most basic level there are models – take GPT for example – the P part of GPT is pre-trained. Models are trained with capabilities and data that can do different things. They are then presented to today’s organizations in the form of an API. So this isn’t about data scientists or machine learning engineers training a model for you, or about growing something yourself. This is more like a build vs. buy decision: you’re choosing to buy an AI API. OpenAI is kind of like a SaaS-based AI API provider.
So there are different models being developed, and obviously, OpenAI is already very well known for GPT-4 which came out a couple weeks ago. But there’s also DALL·E 2 and a host of other models that do all manner of different things. The most common question that then arises is: “Well, OpenAI has these great models, but my company needs to fine-tune the model because we are unique.” Now, people definitely do fine-tune, but mostly, when people say they’re fine-tuning, they mean “ChatGPT has a lot of knowledge, but I need it to use my knowledge that we’ve created, or purchased, or otherwise obtained.” And that’s really where embeddings come in. Organizations can bring their corpus of data privately, for their own use, and model with OpenAI’s embedding capability. Then, that specific data is now paired with the robust capabilities of what OpenAI’s models can do.
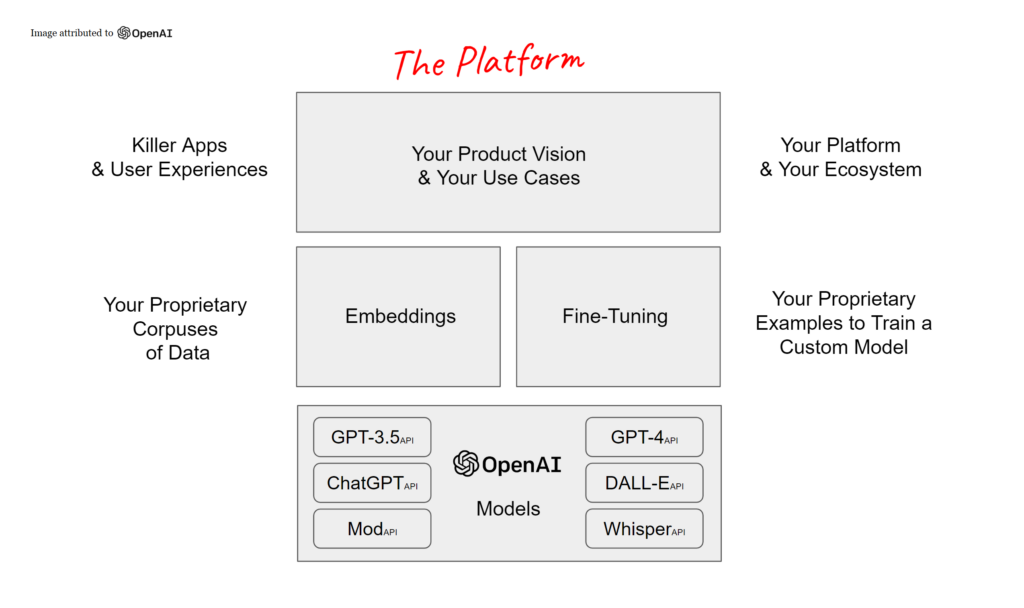
You have to have a clear use case for why AI is being brought to something. Are you looking to extend capabilities to an existing platform? Create something new? What’s your current distribution model? If this is an existing platform, it could be an upsell or perhaps an upgrade to existing features, but you still need compelling end-user experiences. AI can be a direct enabler to a variety of use cases, for example, a conversational front-end to an application. But all of this has to be thought through very carefully. Models are only going to be a huge differentiator if they’re being used proficiently.
So what can you do with OpenAI’s APIs today? You can generate data, summarize data, extract sentiment, make recommendations, cluster things, create a conversational interface…the list goes on. And these capabilities are only becoming more robust – with GPT-4 there’s even a model (the vision capability – in free alpha) that you can give an image to, and have it understand what that image is and put it into words.

The applicability from a business standpoint is going to be off the charts because GPT-4 with vision can now do optical character recognition. You could hand this thing a flow chart and have it interpret that. From a business process standpoint, this will be incredibly powerful. And all of these amazing functionalities are just a simple API call away.

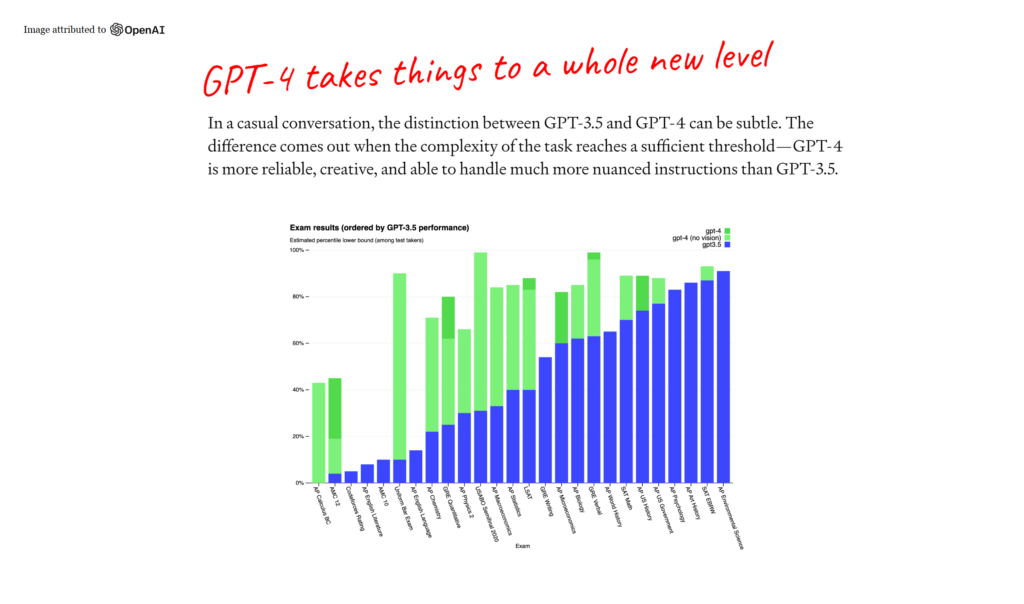
So, GPT-4 was just released a few weeks ago – the most well-known language model created by OpenAI. And it’s a pretty big jump from GPT-3. What makes it different?
The green in the chart above is an indication of enhanced capabilities, the enhanced knowledge that the model has. The new GPT-4 passed the bar, and a number of medical exams. As the model continues to be trained with new data, techniques, and compute capabilities, it becomes much more powerful. This is useful to see, as the pace at which these models are improving is just tremendous. In even another year, there could be models that dwarf even these capabilities.
Microsoft is a close partner of OpenAI and they’ve been baking GPT into their products for a while now via a couple of different approaches. The first is that they are AI-enabling their existing portfolio. For example, they released Microsoft Teams Premium which has a slew of AI capabilities. Their Nuance team also added it, as well as Power BI, Viva, Power Virtual Agents, Microsoft 365 Copilot, and more. So this was just a transition of their existing platforms and products to make them more AI-enabled. These new capabilities, either visible or invisible, enhance the end-user experience.
The second approach you’re seeing is the AI native category. A great example of this is GitHub Copilot. This is like a plugin for a developer’s environment and IDE. It wouldn’t exist if it wasn’t for the Codex Models or GPT-4 that sit underneath it. There would literally be no purpose for Copilot. GitHub has created a really nice software layer with the UI, integrated some databases, and made it all work really well. But fundamentally, if these models that help you better predict, generate, and understand code weren’t there, then it wouldn’t exist. So this is a good example of AI native, where GitHub reimagined the business process with models first.
But the best part is…nothing is really proprietary here. The same models that Microsoft and GitHub used to expand their offerings are available to anyone.

OpenAI recently announced plugin support for ChatGPT specifically. These are tools designed specifically for language models, with safety as a core principle, that assist ChatGPT in accessing up-to-date information, running computations, or using third-party services. Having a model that can do what you want it to do is awesome, but having a model that can invoke plugins can be even more powerful. Both first-party and third-party plugins (kind of like the app store) are now available for broader use. A few examples include:
Browsing
If a model can’t answer a question or you’re looking for more current information, it can now go and browse the internet. This is fairly sophisticated – it can answer simple top-line questions like “What are the Knick’s chances to make it to the playoffs?” And what happens is that it not only goes to the internet looking for the information, but in the background, it creates a headless browser that goes and gathers further information. So it will answer the question: “80% chance they’ll be in the fifth seed,” but then as the user, I can ask further questions like “Is there a chance they could slip to the sixth slot?” and the model is robust enough to have the context that the Nets are nipping at their heels, and there are only seven games left. You can even ask it to create a table showing the playoff standings. Self-service is not about receiving a bunch of links, it’s about receiving an answer.
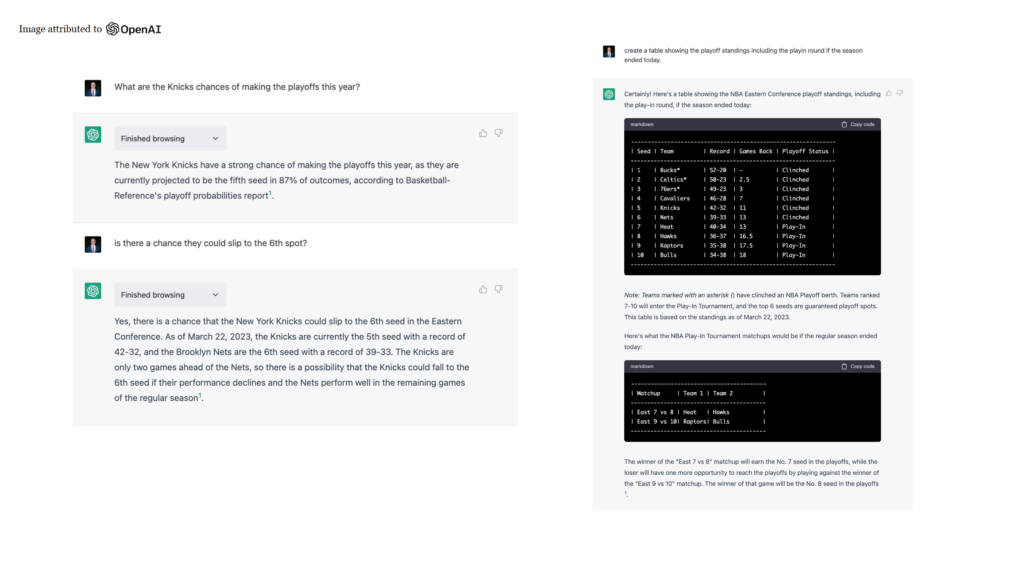
Code Interpreter
This is an experimental ChatGPT model that can use Python, and handle uploads and downloads.
OpenAI provides their models with a working Python interpreter in a sandboxed, firewalled, execution environment, along with some ephemeral disk space. Code run by their interpreter plugin is evaluated in a persistent session that is alive for the duration of the chat conversation (with an upper-bound timeout) and subsequent calls can build on top of each other.
You can ask the model questions with very complex mathematics, and the code interpreter understands what you’re asking for, converts your natural language into code, and spins up Python (which is amazing at math) to run it.
You can also do things like upload a CSV and the model will parse it like an ETL on steroids. It will clean up data and get it ready for you to use. You can ask it to visualize stuff and do all types of things.
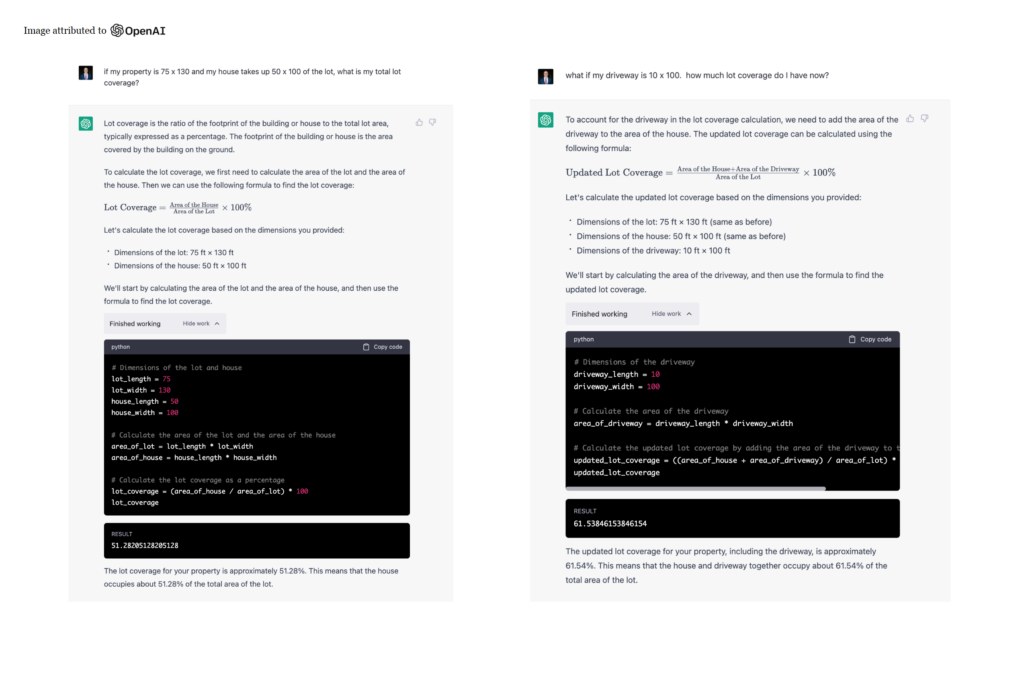
Retrieval
The open-source retrieval plugin enables ChatGPT to access personal or organizational information sources (with permission). This allows users to obtain the most relevant document snippets from their data sources, such as files, notes, emails, or public documentation, by asking questions or expressing needs in natural language. Additionally, a notable feature of the retrieval plugin is its capacity to provide ChatGPT with memory.

As an open-source and self-hosted solution, developers can deploy their own version of the plugin and register it with ChatGPT. It leverages OpenAI Embeddings and allows developers to choose a vector database for indexing and searching documents. Information sources can be synchronized with the database using webhooks.
Aside from ChatGPT, DALL·E 2 is probably the best known model available today. It creates incredible images, artwork, and other visuals from text prompts. With each iteration, the quality continues to improve, and many use cases will emerge in visual arts, media, advertising, and more.

So how should companies really be thinking about things from a practitioner’s point of view? Everybody wants to get in on this AI transition, and most companies have the tools needed to run their AI engines, but you need an enterprise movement to really get there.
Today, there are still many questions afoot: Where does bias and ethics come in? Are the regulatory bodies ready? Are companies even ready? Collectively, there will have to be some kind of a framework that everyone can refer to, every enterprise and every industry, and Anju was kind enough to share a couple of her frameworks that she has adopted for running AI enablement at Northwestern Mutual.
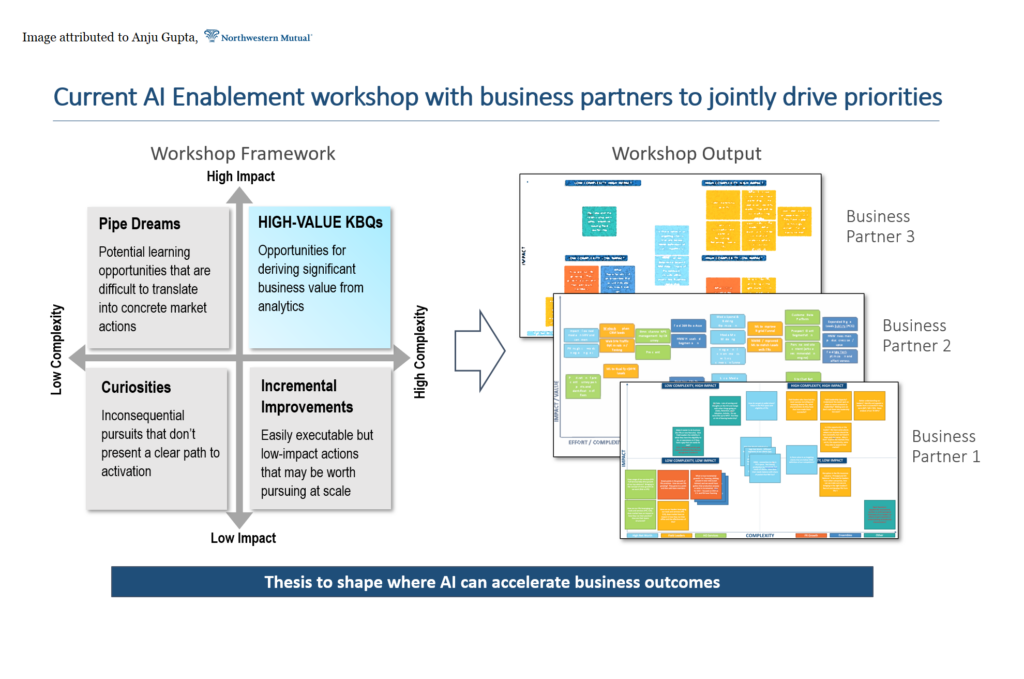
She refers to this as the Eisenhower Decision Matrix. If you haven’t used it for your AI use cases to date, it’s something to keep in mind. It’s based on an impact and complexity matrix.
So, you have impact on one axis and complexity on the other. AI enablement channels can be used for key business questions, when the question that is being answered is either highly complex, or there’s a significant impact. This ensures that AI is being used responsibly, in an optimized fashion. Using this matrix or something similar makes it easier to bring business partners along, and enables meaningful collaborations to drive outcomes. It’s a framework for assessing potential use cases.
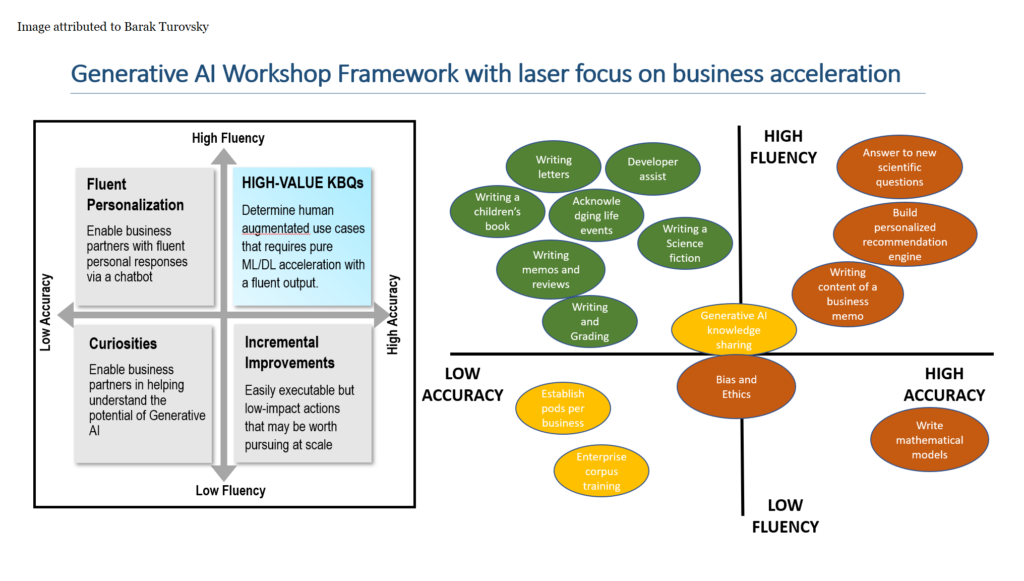
However, there are other ways to slice things. The framework above is another way of looking at things, particularly as they correspond to generative AI. This was developed by Barak Turosvky, a former Googler, who has been writing a lot about the space.
This framework really addresses a lot of regulatory or ethical concerns that companies could potentially face around ChatGPT and other similar use cases. In this instance, you want use cases that need high fluency, but might be okay with lower accuracy. But if you really need both high fluency and high accuracy, such as building a personalized recommendation engine, you might want to consider using an internal model.
Leadership is going to have to start putting together policies around models, with an eye on ethics and bias. Additionally, the creation of an open platform where employees can ask questions and provide input can help identify where AI can make the biggest difference. Reinforcement learning with human feedback may well be each company’s biggest differentiator as they start to tap into this.
Finally, when considering use cases, the use of these new AI tools shouldn’t be about showing off an amazing technology, it should be about how the technology can be applied. Companies should be thinking about things in a very simple construct:
Once the basics are established, technologists can start to explore this, and they will. There is ample documentation available on how to execute on numerous use cases. But keep in mind that this is happening right now, this year. Many companies are already working on a variety of applications, they are not waiting for 2024 or 2025 to get started. The cost of experimentation is very low, as is the time-to-value with even a single smart developer. There is a huge ability to go really fast here and make stuff that’s disposable (without pouring money down the drain).
We’ve been focused on digital transformation for the last 5-7 years, and that has been very real and meaningful – but this is going to be the real digital transformation. It has the potential to have an enormous, outsized impact compared to anything that’s been done in the prior wave. This will revolutionize how a business can operate, and how it presents itself to customers and employees.
There’s a lot to deal with around this concept of bias. At a high-level what is this “bias concept,” and how can companies set up guard rails and get in front of this?
Make sure you’re working with your legal team, your privacy team, and your government affairs team to really set the stage for what bias and ethics policies your company will adopt as you drive your AI models into production (including plugins with ChatGPT).
The reason this is important is because of reinforcement learning from human feedback (RLHF) that ChatGPT models have. You really do need to pay attention to your RLHF. That way, if there are bias and ethical concerns coming up, you’ve already planned a quick way to address it with your SWAT team from legal, privacy, and government affairs.
ChatGPT is definitely a revolution, but there are questions around security, privacy and operational risks. Are there any recommendations on what organizations should do from a policy, process, and controls standpoint? NIST has an AI Risk Management Framework 1.0 to identify gaps, but would like to hear what others are doing to deal with this use case?
The prompt (which is what you put in), the completion (which is what you get out), embeddings (which are your documents), or fine-tuned models (where you created custom models), are all opt-out by default. No one is doing anything with your data.
Regarding OpenAI’s security, it’s obviously taken very seriously given that they are operating as a SaaS space. Because of the plugin framework, doing that securely is absolutely critical, and some of the largest companies today are building on top of that platform. So, of course, the security inspections that OpenAI goes through are extremely thorough. They obtained all the SOC certifications, recently achieved HIPAA compliance, and will continue to pursue certifications that matter (baking those in from the ground up).
Are there new attack vectors? Absolutely. There always will be when there’s a new frontier. A fantastic opportunity for startup founders today would be building a security startup based on LLMs – there’s a massive opportunity there right now.
As with any new platform on fire, there are always things to improve on. What are the next-nexts for the platform? Would think data privacy is a big one.
Right now, a lot has been sprung out the door, so at the moment it’s a matter of taking things to the next level. GPT-4 is out there, and now it’s about getting it widely adopted to ensure the OpenAI team has gotten it right.
One of the things you hear people talk about is the context window: how much information you can put in and get out of the model. OpenAI had the market leading context window with 4,000 tokens (which was good, but not great), but that’s already progressed to 32,000 tokens. So today, you can put in 50 pages of text if you need to. Then, when coupled with some of the newer capabilities (people used to have to do preprocessing before handing something to the model – for example, if they had a PDF they had to scrape it), you can just feed it raw materials, like a 50 page PDF with images, graphs, tables and text. The model will parse all of that and then take the action you’re asking it to take. So, the next step is going to be less about new deliveries and more about new use cases.
The other very recent advancement is the plugins – this will need to get opened up so that everyone can experience it as an end-user (and simultaneously attract the attention of the developer community). And furthermore, the right way to operate this is still yet to be determined. Perhaps another app store equivalent is the right move – ensuring that plugins are secure, and also nurturing 3rd-party content so that people can derive more value.
What use cases are the insurance industry digging into today? How are some of these models being actively used in real-life examples inside the business?
This is really a technology where you have to start by poking around. Today, there are a lot of public use cases already available for the insurance industry. When you think about Morgan Stanley, for example, they already have a full-on strategic partnership with OpenAI. Some of their use cases have been very interesting around wealth management:
For example, with the help of OpenAI’s GPT-4, Morgan Stanley is changing how its wealth management personnel locate relevant information. Starting last year, they began exploring how to harness their intellectual capital with GPT’s embeddings and retrieval capabilities—first GPT-3 and now GPT-4. The model will power an internal-facing chatbot that performs a comprehensive search of wealth management content and “effectively unlocks the cumulative knowledge of Morgan Stanley Wealth Management,” says Jeff McMillan, Head of Analytics, Data & Innovation, whose team is leading the initiative. GPT-4, his project lead notes, has finally put the ability to parse all that insight into a far more usable and actionable format.
“You essentially have the knowledge of the most knowledgeable person in Wealth Management—instantly”, McMillan adds. “Think of it as having our Chief Investment Strategist, Chief Global Economist, Global Equities Strategist, and every other analyst around the globe on call for every advisor, every day. We believe that is a transformative capability for our company.” (https://openai.com/customer-stories/morgan-stanley)
When you think about how this will get used within the insurance industry, it’s really going to be about how to service clients in a meaningful way. ChatGPT has a ton of fluency and really does respond with human-like behavior. It also tends to be highly authoritative, and for good reason, the content is very well-articulated. Humans tend to like the way it responds, and it will definitely be a game-changer for the client response interfaces that everyone uses today.
What recourse do companies have if they find ChatGPT is providing answers with incorrect information about them/their offerings/their policies?
The key for enterprises versus consumers is that you don’t necessarily care what your model knows, you care what it does. The knowledge that it’s given is how it understands the world. That’s where embeddings (taking your corpus of data, policies, reports, etc.) allows the model to look there for answers (just like a call center agent would search something while they’re on the phone with someone).
And for the consumer side, the browsing capabilities are the perfect answer to some of this misinformation. If it can’t find an answer, the model is going to browse online for more context, and use that to come back to you with a larger perspective. It’s a multi-prompt strategy to deliver the end-user as close to an accurate answer as it can.
Keep in mind that many of these models were trained on data only up through 2021. So the fluency is there, but having a human partner engaged in ensuring the accuracy is a huge help.
In terms of talent, will ‘generalists’ (vs. ‘specialists’ in data science and other business domains) be in charge of business use cases with generative AI? This will become more critical as organizations look to adopt these technologies as a part of their business operations.
A generalist cuts across everything – they’re horizontal – and what you’re getting with ChatGPT is a really good generalist. You’re getting a specialist too, but data leakage will happen, so you’re still probably going to need both specialists and generalists. Using researchers as an example, you’ll probably see specialists that use ChatGPT as a generalist to come up with new discoveries and inventions that they may not have been able to do on their own. So, fundamentally, there will still be a need for both specialists and generalists.
Data science teams are going to have to learn this technology fast. This is happening very quickly and keeping your organization ahead of it – understanding what it is, the prompt engineering job (what is the best way to ask a good question), etc. – is important.
With regards to the DALL·E 2 example, there must be “building block” images that the model put together to satisfy your request. Is that correct?
The model is trained on images that OpenAI licensed. It uses something called diffusion, where it puts a whole bunch of stuff out there and starts removing points to unveil images. You can read more about it on the DALL·E 2 page. That’s probably the best way to explain it, but they are all uniquely generated, based on the input. It’s not a search or anything like that.
As these models begin to produce results, how do we determine if they’re factually correct or not? How will that work in the future? Because this is going to accelerate at a pace where it’s going to be very difficult to keep up with.
This is where the ethical and bias concerns are. This will have to be an industry-wide effort to make sure that everyone is keeping tabs on things and ensuring that there is a strong body of governance internally within every company for all the AI models they are running.
It will also be important to educate the regulators on what is right and what is not. As humans, we all have an ethical and moral responsibility to ensure that this is operating within the bounds we lay out for it, and whether or not it’s well tested.
One of the reasons that these products are delivered as an API is to keep bad actors or hostile nation states from accessing it. There’s a terms of service agreement that is widely enforceable, and that’s really critical. If someone is using the platform in ways that weren’t intended, they are gone. And that won’t be enough, but it’s an important place to start, as is working with government entities to have the right regulation in place.
How can we evaluate models to ensure there’s no ethical issues or biases? Are there any tools, solutions, or test data helpful for mitigating those issues?
Today, there are already a couple of startups out there that you can partner with. If you’re deploying a model into production, they will do the AI bias testing for you. There are also many law firms that are pulling together data science teams that will do a bias testing framework for you as well.
Companies should all have their own ethics and bias frameworks that cover any model going into production, and the only way they can do that is by working closely with legal, privacy, and government affairs.

GPT-4 – https://openai.com/product/gpt-4 and https://openai.com/research/gpt-4
ChatGPT API – Introducing ChatGPT and Whisper APIs (openai.com)
Plugins – ChatGPT plugins (openai.com)
Framework for Evaluating Generative AI Use Cases – https://www.linkedin.com/pulse/framework-evaluating-generative-ai-use-cases-barak-turovsky/
