

We recently hosted our latest CXO Insight Call: “CXOs and Gen AI – An Investor Perspective on the Technology Breakdown,” morning of Tuesday, October 31st, where we hosted Vijay Reddy, Partner here at Mayfield, and Isaac Sacolick, Founder and President at StarCIO. In our content below they speak from an investor and practitioner’s perspective on the tremendous opportunity and ongoing adoption of generative AI, which is driving a new AI-first enterprise IT stack.
IT leaders across all industries are already thinking about what their top of mind priorities will look like, including how they plan to educate and experiment, manage their blue sky planning, update data governance policies, and so much more. Isaac and Vijay discuss what they’re hearing from hundreds of tech executives in the market, and cover many urgent questions around LLM adoption and strategy.

Vijay has been a fantastic addition to the Mayfield team, joining us from Intel Capital earlier this year as our new AI-focused partner. His investor journey began in 2014, which just so happened to be the same year that deep learning began smashing through some fundamental benchmarks. This marked the early innings of the deep learning era. During that time, trillion dollar markets opened up across a variety of different industries. AV, medical, satellite imagery, and so much more greatly benefited from these disruptions. It was a ten year investment period for many AI-focused firms.
A recent survey in McKinsey suggested that the technological advances we’re seeing in AI today are ten years too soon for a variety of different use cases. This includes rote tasks such as math or coding, but also cognitive activities that are further afield, like dialogue, video generation, and a higher order of understanding and interpreting natural language. We’ve reached the point where we’re going from repetitive tasks to cognitive tasks – this is a big moment, especially when looking at very large markets.
AI won’t necessarily replace humans, but humans utilizing AI may be substantially more productive than humans who aren’t. And because of the human aspect of all of this – the markets that AI will be replacing have to be considered differently. People tend to look at markets and say: “What is the TAM for accounting software?” But in the case of AI, they’ll have to say “What is the TAM for accountants?” and start working back from that. That’s around $20B, when the software TAM is only a few hundred million. So startups are primarily approaching markets that have huge human capital, and are trying to greatly augment humans within those markets.
In the last cycle, as mentioned prior, AI started with the data scientists and eventually trickled down to the business users, but now we’re seeing the reverse. Business users are eagerly coming up with use cases that are then passed down the pipe to IT, data analysts, and data scientists – with the implication that they will come up with a solution. Because business users are the originators however, there is an order of magnitude more people touching AI in their daily lives, and who are willing to go to bat for it on budget.
Another big difference is that in the past companies had to build enterprise applications very tailored towards one persona. If you were a product company (as opposed to a sales company) the data sources would be entirely different. But now, some of these new gen AI companies are cutting across different use cases, budgets, personas, etc.
Finally, as models continue to scale up, emergent behavior may continue to unlock new use cases.

We’ll see a lot of capital go towards enterprise infrastructure, and even though the number of deals has slightly decreased, the funding has very much increased. What that indicates is that a few companies, particularly the model building companies, have raised a lot of capital. This makes sense: they’re competing with the giants – they need better algorithms, compute, data, etc.
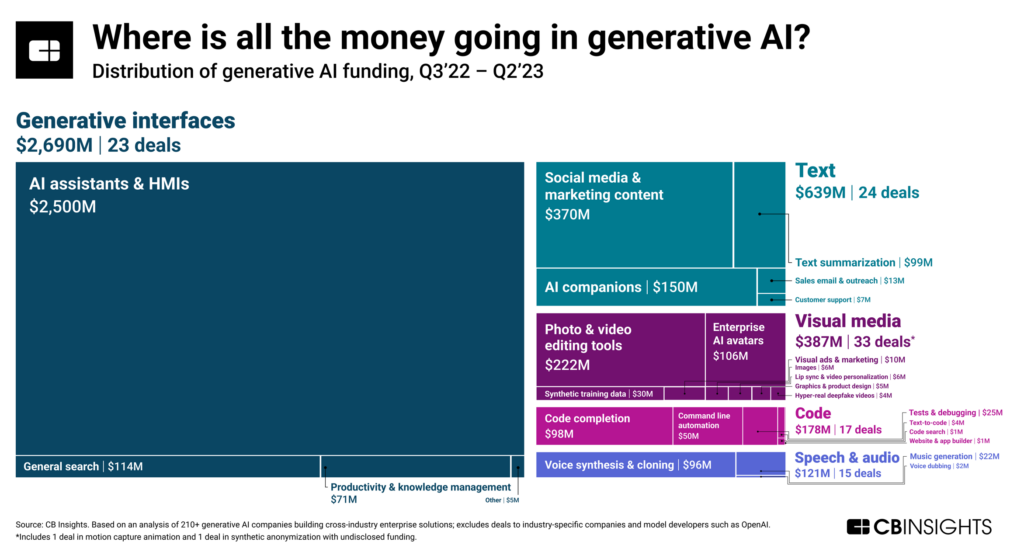
This is roughly where the capital is being allocated today, but it will of course continue to change over the next 5-10 years. We’re seeing a lot of copilots, a lot of AI assistants, and a lot of focus on marketing and sales. Right now we’re at the peak of the hype cycle, but that will change over time. Startups today are out there building as many different hammers as they can, and then going out to look for nails. Practitioners must help identify where those nails really are.
On the fundraising side, we’re seeing a bimodal distribution. Some startups with just a couple million dollars can use gen AI to get to an MVP really quickly because they’re using open source tools or publicly available datasets. On the flipside, if you created your own model you have to raise a lot more, like a $20-$40M seed raise before you can even start selling anything. So the bifurcation is really between companies who are building models vs. those just taking things to market directly. Text is very oversubscribed right now, but videos, images and music are all wide open.
Pressure from the top means that organizations are going to have to come up with their AI strategies in a bit of a hurry. And they’re not wrong, generative AI is likely to make a significant impact in IT. The same way that mobile devices in the past led to the consumerization of IT, generative AI is leading us in the direction of the consumerization of search. Unstructured content and documents can now be used to make customers and employees better informed and more intelligent. IT should already be leveraging some of these capabilities today, including things like:
CXOs should start by getting a ground floor view of what people are experimenting with, or what people want to experiment with. IT and marketing are two fruitful areas with a lot of tools and built-in platform capabilities that you can take advantage of.
The second step is building out guidance with IT leaders within the organization, especially where there is risk around sharing IP. Take a look at what people are doing with the tools you already have. All the big players like Atlassian Intelligence, GitHub, Adobe, etc. are starting to include point solutions for generative AI that give you a narrow, siloed view of your enterprise data. And now you can use it for things like answering a service desk call, or processing information, or doing a search within your Gira tickets. There are a lot of quick and easy things to do.
Finally, from a developer’s perspective, it’s time to start thinking about how to make your own data accessible to LLMs before you even consider building your own. And as you dive into that technology you’ll start to see a lot about vector databases, embeddings, etc. and that will take your information sources, compact them down to a vector type of information (whether you do that yourself or with tools as the tools mature), and enable you to plug your data into either private, industry, or open LLMs so you can start making really intelligent decisions around that data. Things to bear in mind:
As CXOs start going up the stack and thinking about AI strategy and how it should be presented, there are a few things to consider:
Data governance
Guardrails
Communications
First of all, this is something that needs to be considered on a timeline of 2-4 years down the road. Places like healthcare, education, etc. that have large untapped corpuses of IP (that have probably remained untapped over the years because the focus has been on relational data and analytics) can now be prompted against.
CIOs will need to project where their specific IP is going to offer advantages and how that will play out across their industry. This is the first step in defining a game-changing LLM strategy. The second piece of that will of course be cleaning and prepping data for those private LLMs.
Finally, there’s a notion that AI is going to take over for humans and make everyone’s decisions for them, but this really comes down to figuring out where decision-making authority really lies. Machine learning and LLMs are only aids in helping people make smarter and faster decisions.
The board will be asking a few different questions that CIOs should bear in mind:
IP, data and content behind the firewall
Experimental culture, personalized experiences and workflow
Governance: who and how
Every software company is in a race to hook up their apps to Open AI, but you have software for CRM, ERP, HRS, and all kinds of other use cases. Is there a world where there will be specific LLMs we plug our business processes into? Not just Open AI, but very specific LLMs?
Eventually every endpoint will have something like an agent, whether that’s a CRM or otherwise, and a lot of the open source community is currently in the process of building these agents. And we believe that at some point these agents will start communicating with each other. We don’t have the frameworks yet for that, but someday your sales agent may start communicating with your marketing agent.
What is the role of data going to look like going forward?
Large enterprises are now well aware that data is the moat, and most startups have now recognized that enterprise data is where they want to play. So, there’s definitely a lot of tension today between incumbents who are trying to get insight into their own data (and monetize it) and startups, who are getting really smart about how to get at that data (even combining the data from many different companies – creating positive network effects). One question will be whether or not enterprises team up to create industry-specific LLMs themselves. Technology isn’t what will hold things back – it will be trust.
With the value of data now clearly understood by all, could there be a mid-market kind of play for matching and consolidation and aggregation of data?
If a startup wants to have a competitive moat, but you can scrape the web using an open-source model, the moat for that company won’t be in the technology or in the data. So, we encourage startups to think about how they can get access to private pockets of data. For example, looking at healthcare and genomics, there are a number of companies trying to aggregate some of these data sources. Unfortunately, this requires a lot of work with the other players across the ecosystem in order to successfully make things happen. This could be legal/privacy-related, or it could be that company business models themselves are prohibitive.
What are the primary use cases where enterprises can get started? Seeing some early innings in SecOps, DevOps, Code Generation, Data Analytics, etc.? But in classic IT functions, where should we be looking for time to value?
These are very similar use cases to what we are seeing. From a non-IT standpoint, we’re also seeing a lot in the back office. Front office will be slower because there’s the issue of having a human in the loop, but in the back office we’re starting to see things like software developers becoming more proficient with tools for code development and code completion, as well as code search. There are also a lot of different companies looking at different data sources across IT, and extracting insights from that. Five years out we’re going to see more agents being used.
We’ve deployed Claude to our entire company and everyone is using it for summary and query-based use. We don’t need to go much further than that because our other primary business applications are releasing AI functionality over the next 6 months. In light of that, do we need to invest in generative AI? Where is this profit coming from that’s expected to dominate the market? A lot of this seems off-the-shelf or free?
One way to think about this is that a lot of the costs today are still being figured out, and companies large and small will want to know if customers are really willing to pay for these extra features (or not). Today things are still being subsidized and companies are still in the ideation phase, but eventually everything is going to settle out and it may not be so inexpensive to ride along with the majors.
How do you communicate around concerns the workforce might have regarding how this could impact them or their role?
We’ve had this struggle every time there has been a technology that moves up the stack and challenges the types of things that employees are doing. Whether that’s robotic process automation or low code technologies, there is always wariness around this method of moving up the stack. The CIO formula around all this is fundamentally simple to say and hard to execute. It’s really about bringing people together, making reasonable projections over what people will be doing with these technologies over the next 6-18 months, and then really thinking through what people’s jobs are going to look like when that surfaces, and how you will really need to wind up training and preparing people to do things differently.
With the rapidly changing pace of technology, employees will need to learn new skills, but which skills, and how quickly? There is a plethora of learning all around. Furthermore, the standard way of learning (going to school) is somewhat ineffective in the current circumstances. So how are universities adapting to this kind of change? And how is AI actually being used to create new kinds of personalized learning?
In terms of employees and learning, this can seem chaotic, and in some ways you want a little bit of chaos in terms of giving people the freedom to ask the right questions. But putting down some governance and figuring out what tools and what data people should have access to is important as well. You want to open up the floor to your employees to ask a lot of questions, and then narrow things down and say let’s apply our learning activities in these initial channel areas, let’s provide some tooling around how you can collaborate and how you can share your learnings, and most importantly put some structure around the data and tools that people are using. Start with a wide funnel and then narrow things down around how people should spend their time.
Education in general is going to run up against a lot of disruptive factors, it should have already over the last few years, the pandemic was the spark in terms of how people were learning virtually. And now, when you think about the education of the future, it must include prompting, and the creative exercises necessary to help educate people in their future roles. We went from digital natives, to now, AI natives coming into the workforce over the next ten years. Higher ed in general will ideally want to take advantage of this new technology, instead of persisting in a linear learning model.
What is the balance between moving fast and moving securely? How will these regulations be consumed on the startup side and at the enterprise level?
The one thing we have to learn from the past is that saying no and locking out employees from doing anything in the space is a recipe for disaster. The hard thing this time around is going to be getting ahead of the board (and those same employees) and saying “Look, here’s the playground, problems, and who and how to collaborate.” Finding some good fruitful areas and saying “Let’s focus here first,” is a good start. There’s a lot to be thinking about like the lack of explainability, and the lack of attribution that these LLMs are doing today. When we do machine learning and analytics we know how to create synthetic datasets, do automated testing around it, and start seeing how the boundaries work. There’s still a lot of technology and know-how and skill to be able to do that, but those tools don’t even exist for LLMs yet. So if we create an LLM with whatever level of expertise it has, where do its boundaries begin and end in terms of what questions it can legitimately answer? We don’t have a good answer for this today. So that needs to be top of mind when talking about LLM Ops. Is this particular LLM with this data ready for production use? Or what level of production use is it ready for? I don’t know if Google and Open AI’s open approach of seeing what happens and cutting back if they run into issues really works well in the enterprise. So you have to take things slow and think about the data governance side of it, while making your IP ready for vectorization, and for embedding, once LLMs get to where they need to go and there’s good technology out there to do validation.
What are your thoughts on what came out of the White House yesterday?
From an investment standpoint this is very exciting news. We’ve been looking in data ops quite heavily, including PII data and access control. From the model standpoint, we’re thinking about things like: How do you score a model? How do you red team/blue team a model? How do you add guardrails to a model? How do you reduce hallucinations in a model? These are all very exciting investment opportunities for us and our goal is to definitely help address some of these issues. But, we think it’s an evolving space where regulations will change. Eventually enterprises could need insurance, or protections, or who knows. But these are going to be very dynamic and interesting challenges that both enterprises and startups alike will need to react to.
The good news here is that the government is getting involved. Yesterday was a lightweight first step in creating a directory and technology companies should be open to doing that. As the government learns more, in the back of their heads, they want to make sure that the people of the country are safe and that our intellectual property is safe. But just like on the enterprise side: We can’t sit back and wait. Our adversaries will be implementing these same technologies with far fewer regulations and scruples around them. So, we need to keep the innovation going, but start learning what the government’s role should look like as capabilities continue to expand.

